import subprocess
import sys
# 必要なライブラリをリストにまとめる
required_libraries = [
'json',
'pandas',
'matplotlib',
'pytz',
'ipywidgets',
'numpy',
'seaborn',
'ipyfilechooser',
'plotly'
]
# ライブラリのインストール関数
def install_and_import(library):
try:
__import__(library)
except ImportError:
subprocess.check_call([sys.executable, "-m", "pip", "install", library])
__import__(library)
# 各ライブラリのインストールとインポート
for library in required_libraries:
install_and_import(library)
# インポート文
import json
import pandas as pd
import os
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Yu Mincho', #'Hiragino Kaku Gothic ProN', #'Meiryo', #'Noto Sans CJK JP'
import matplotlib.dates as mdates
import pytz
import ipywidgets as widgets
import numpy as np
import seaborn as sns
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
from ipywidgets import DatePicker, Button, HBox
from matplotlib.lines import Line2D
from pytz import timezone
from IPython.display import display, clear_output
from ipyfilechooser import FileChooser
from datetime import datetime
from datetime import timedelta
print("All libraries are installed and imported successfully.")Google Fitに集約した睡眠データをローカル環境で可視化するJupyter Notebookを作成しました
スクリプト
How2
おすすめ記事
カスタマイズした二重プロットアクトグラムをはじめとした様々な手法で、睡眠記録を分析することができます。

本サイトは広告やアフィリエイトプログラムにより収益を得ています
1. 要旨
Google Fitに集約された睡眠データをダウンロードし、ローカル環境で分析をしたいと思いJupyter Notebook(.ipynbファイル)を作成しました。 このノートブックでは、事前にダウンロードした睡眠データ(.jsonファイル)を用いて、四半期ごとあるいは任意の期間のダブルプロットアクトグラム(+睡眠ステージ), 四半期ごとの睡眠時間及び質の推移, 四半期ごとの曜日別睡眠時間及び睡眠の質, 任意の日付の睡眠ステージの推移を可視化することが出来ます。 このノートブックの新規性として、複数デバイスによる観測に対応していること, 一般的な睡眠分析アプリには見られない「ダブルプロットのアクトグラム」を採用し、なおかつ色分けにより睡眠ステージが分かるようになっているという2つが挙げられます。特にダブルプロットアクトグラムを採用することで、従来の睡眠記録の可視化手法では難しかった、昼寝を含む全ての睡眠を直感的に理解しやすい形で表現することができます。
2. 背景
筆者はガジェットオタクであり、両腕に付けていたスマートウォッチや、睡眠マットなど、様々な機器で睡眠記録を(半ば自動的に)記録しGoogle Fitに集約していました。
しかし、Google Fitの睡眠可視化機能は複数のデバイスからの記録を想定しておらず、またクラウドに保存しているせいかレスポンスも非常に悪く使いにくさを感じています。
そのため、睡眠分析に興味はあったもののそのデータを活用するという気が起きなかったのですが、Pokémon Sleepに触発され、もっとしっかり自分の睡眠を分析したいという気持ちが芽生えたためこのプロジェクトを立ち上げました。
2-1. 動機
睡眠データを記録するデバイス・アプリは数多くあります。例えば、Sleep as AndroidやPokémon Sleepなど、スマートフォンをセンサーにするタイプのものは手軽な反面、手動で睡眠記録の測定を行う必要があったり(寝落ちして忘れることも)、バッテリー消費が激しいためスマートフォンを充電し続ける必要があります。
スマートウォッチ・スマートバンドを持っている場合、たいていのものは睡眠記録を自動で付けてくれるため更に手軽(寝落ちして忘れる心配もない)ですが、途中でバッテリーが切れてしまったり、睡眠に本腰をいれてないのか、精度が低かったり分析アプリのデザインがイマイチだったりします1。
その点、Pokémon Sleepで言うところのPokémon GO Plus +や、Withingsの睡眠マット(Withings Sleep WSM02-ALL-JP)は、精度が良くアプリも見やすくて良いですが、睡眠のためのデバイスを買うぞという覚悟(と投資)が必要です。
…と、ここまで長々と筆者の睡眠デバイスの経歴を語ってしまいましたが、これらは基本的に独自の手法・基準でデータ分析を行い可視化します。
筆者のように、複数のデバイスを使っている場合、それぞれのデバイスとセットで提供されるアプリを見比べることになるのですが、アプリが違うのでデザイン(測定項目・グラフなど)は全く統一されておらず、比較は困難です。
また、睡眠分析アプリは昼寝に対応しているものが少なく、可視化の際に昼寝が表示されない・あるいは昼寝を可視化に含めたせいでグラフのX軸が広くなってしまい見にくくなることを不満にも思っていました。
幸い、ほとんどのアプリは睡眠記録をGoogle Fitに自動でアップロードしてくれるので、Google Fitを使えば昼寝の件はともかく複数デバイス問題は解決する…ように思えたのですが、前述の通りGoogle Fitは複数のデバイスで同時に睡眠を記録することは想定しておらず、記録自体は保存してくれるのですが、睡眠記録を確認(可視化)する際に、デバイスAの結果を採用する日もあればデバイスBの記録を採用する日もあるといった感じです。というか、表示できればまだ良い方で、大抵の場合(複数デバイスのせいで)エラーが出るのかタイムアウトしてしまい、結果が見れないことのほうが多いです。
このような背景から、だったら自分で(複数デバイスで記録した)睡眠データを可視化・分析するツールを作ろうと思い立ちました。
2-2. 技術的背景
2024年5月現在、筆者の睡眠データは図 1のように記録・可視化され、集約されています。使用デバイス・アプリこそ違えど、Google Fitにデータを集約している方はこのようなワークフローでデータをエクスポートしているはずです。
肝となるのは、各デバイスで計測した睡眠データを各アプリがGoogle Fit APIに基づいてJSON形式に加工しているという点です。これによりデバイスが違っても同じフォーマットでデータを取り扱うことができます。
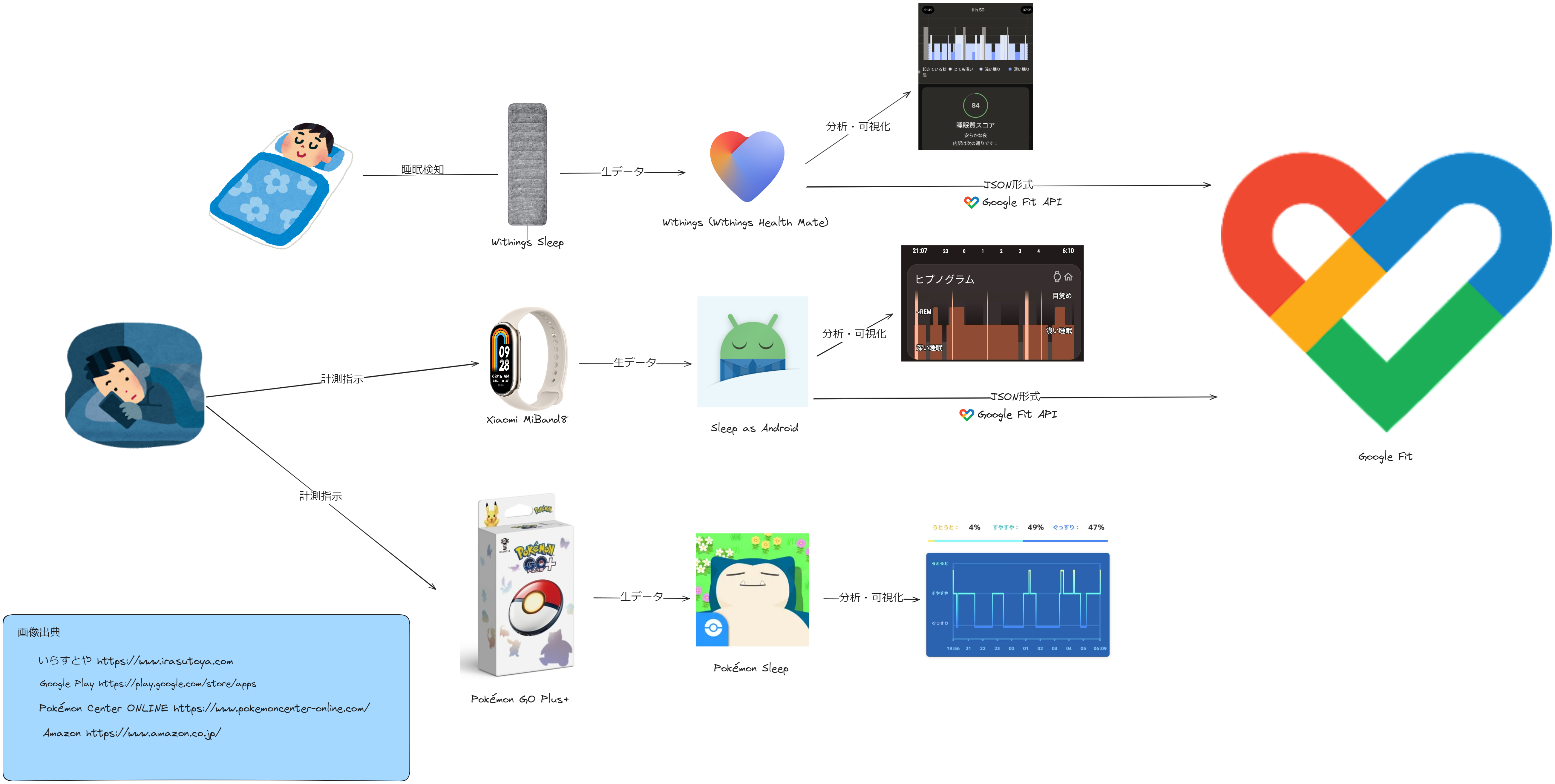
2-2-1. Google Fit APIについて
各アプリ・デバイスで計測した生データは、(Google Fitと連携させた場合)Google Fit APIを使ってJSON形式でアップロードされます。
データには睡眠ステージ, その睡眠ステージの開始時刻, 終了時刻が含まれています。睡眠ステージの判断は大元である各デバイス・アプリに任せられているようです。
サンプルJSONデータ.json
{
"Data Source": "raw:com.google.sleep.segment:com.hoge",
"Data Points": [
{"fitValue":[{"value":{"intVal":1}}],"originDataSourceId":"","endTimeNanos":1620291780000000000,"dataTypeName":"com.google.sleep.segment","startTimeNanos":1620285780000000000,"modifiedTimeMillis":1624604115227,"rawTimestampNanos":0},
{"fitValue":[{"value":{"intVal":3}}],"originDataSourceId":"","endTimeNanos":1620338280000000000,"dataTypeName":"com.google.sleep.segment","startTimeNanos":1620313260000000000,"modifiedTimeMillis":1624604115227,"rawTimestampNanos":0},
{"fitValue":[{"value":{"intVal":5}}],"originDataSourceId":"","endTimeNanos":1620379200000000000,"dataTypeName":"com.google.sleep.segment","startTimeNanos":1620367020000000000,"modifiedTimeMillis":1624604115227,"rawTimestampNanos":0},
{"fitValue":[{"value":{"intVal":6}}],"originDataSourceId":"","endTimeNanos":1620435480000000000,"dataTypeName":"com.google.sleep.segment","startTimeNanos":1620412740000000000,"modifiedTimeMillis":1624604117511,"rawTimestampNanos":0},
{"fitValue":[{"value":{"intVal":1}}],"originDataSourceId":"","endTimeNanos":1620450300000000000,"dataTypeName":"com.google.sleep.segment","startTimeNanos":1620443520000000000,"modifiedTimeMillis":1624604117511,"rawTimestampNanos":0},
]
}睡眠ステージの内訳は以下の通りです(Google for Developers 2023)。
| 睡眠ステージのタイプ | 値 |
|---|---|
| 覚醒(睡眠サイクル中) | 1 |
| 睡眠 | 2 |
| ベッド外 | 3 |
| 浅い睡眠 | 4 |
| 深い睡眠 | 5 |
| レム睡眠 | 6 |
懸念事項として、Google Fit APIが終了しHealth Connect API(?)へと移行されること(Google for Developers 2023)が挙げられます。今後、睡眠データはGoogle FitではなくHealth Connectに集約されることとなるでしょう。データのフォーマットが変わってしまうと、このノートブックの前提が崩れてしまうので、詳細が分かり次第対応していきたいと思います。
2-2-2. Python及びJupyter Notebookの採用理由
何を使って睡眠データの可視化・分析ツールを作るかは少し悩みました。R言語は、必要最低限の読み書きができるものの、ChatGPTをはじめとする生成AIの支援を受けにくいこと, 自分以外の人が使う際に配布・再現しにくいことがネックだったため、Pythonを採用しました。
Pythonは print("Hello World!") くらいしか知らないためChatGPTにあれこれ聞き、最終的にPythonというかJupyter Notebookを採用することになりました。
データの読み込み, データ属性の入力, 日付やデータ期間の選択といった作業を、スクリプトを書き換えるのではなくユーザーが直感的に分かりやすくボタン操作などで行える点(図 2)が、筆者の持つPython並びにJupyter Notebookへの苦手意識を上回ったからです。

2-3. 可視化手法
前述の通り、既存の睡眠分析・可視化アプリには、昼寝に対応しているものが少なく、可視化の際に昼寝が表示されない・あるいは昼寝を可視化に含めたせいでグラフのX軸が広くなってしまい見にくくなる(図 3)という問題がありました。
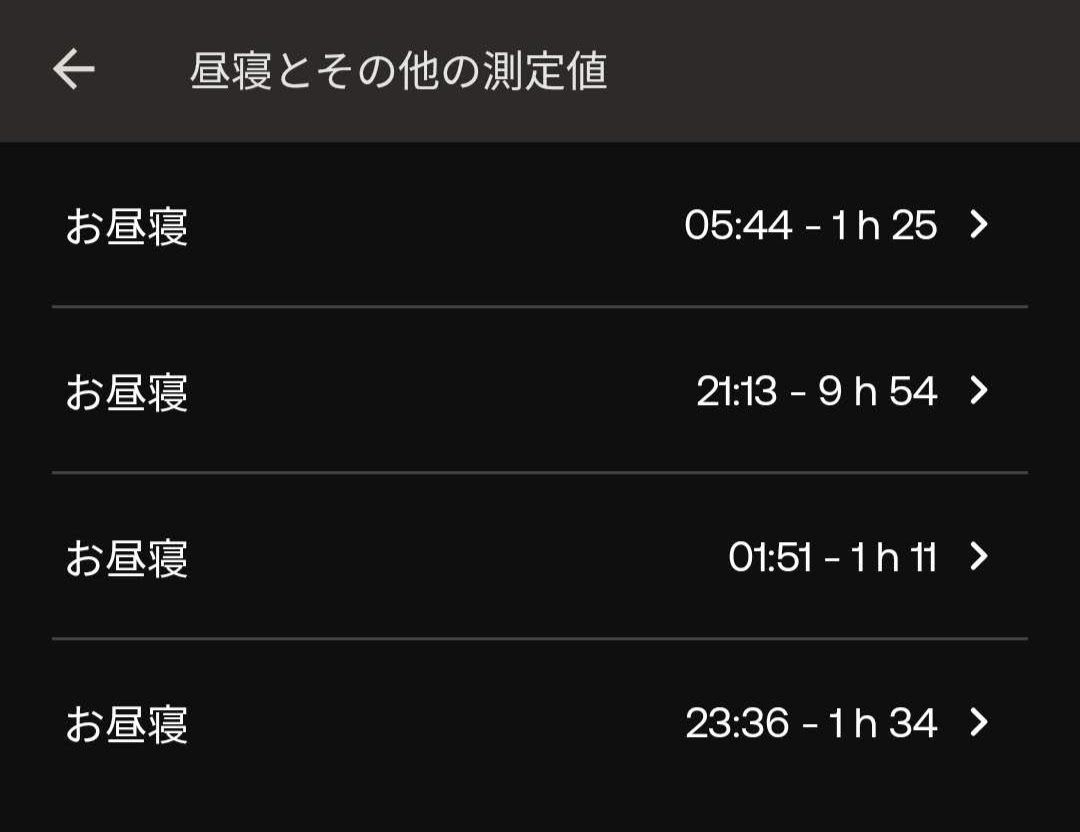
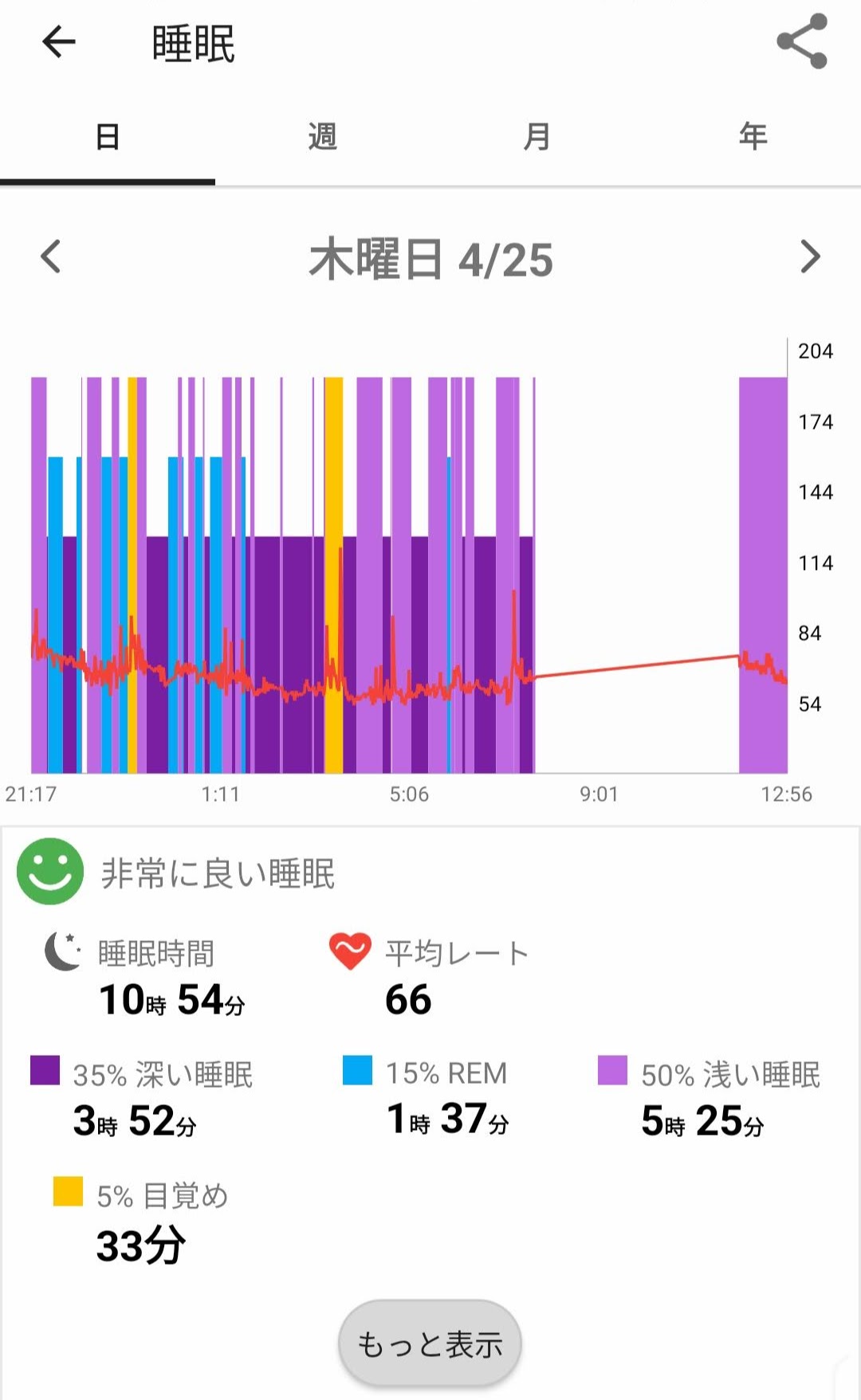
図中、上段はWithings Sleepの睡眠可視化,下段はXiaomi MiBand8のサードパーティアプリNotify
他にも、例えばPokémon SleepやSleep as Androidの睡眠周期の可視化手法には、軸が24時間以下なのでイレギュラーな睡眠に弱く、その範囲を超えてしまうと見切れてしまうという問題があります(図 4)。
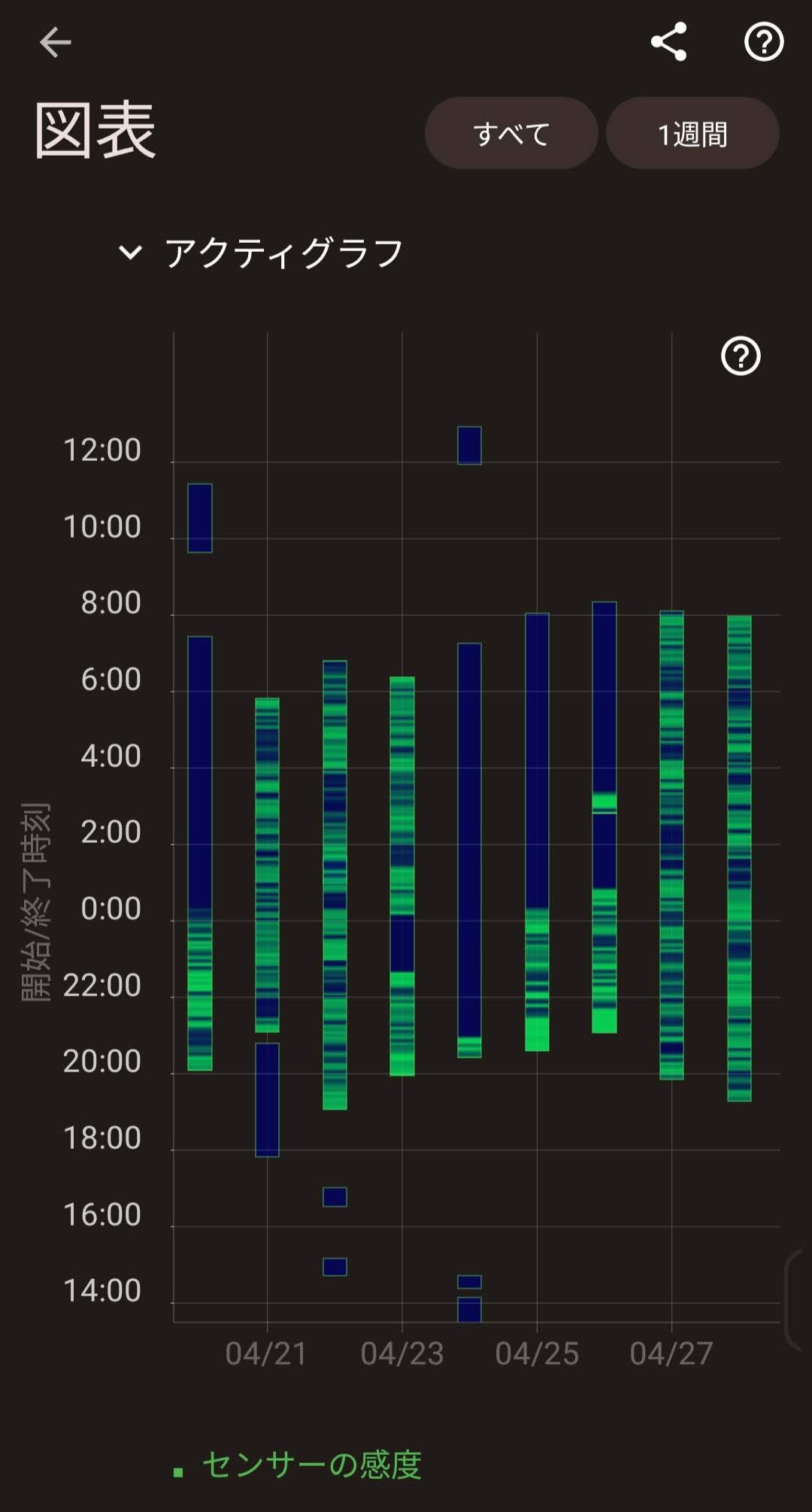

図中、左はSleep as Android, 右はPokémon Sleep
こうした問題(図 3, 図 4)を解決する可視化手法が、ダブルプロットされたアクトグラム(+睡眠ステージも色で表示した筆者オリジナルのもの)です(図 5)。

.ipynbファイル)を参照筆者は生物学を専攻していたこともあり、このアクトグラムというものを概日リズム(サーカディアンリズム; circadian rhythm)の説明の中で知りました。
概日リズムというのは要するに体内時計のことで、恒常環境下(例えばずっと真っ暗闇な状態)でも約24時間の周期を示し, (光)同調性を持ち(光によってリセットされ), 温度補償性を持っているものとされています(Carl Hirschie Johnson & Foster 2003)。概日リズム自体はそれ以前より何となく知られていたものではありましたが、概日リズムの基礎となったのはモデル生物であるショウジョウバエを使った研究で、そのルーツは時間生物学(chronobiology)の創立者の一人であるコリン・ピッテンドリー(Colin Pittendrigh)であると言えるでしょう(Tataroglu & Emery 2014)。
概日リズムやそれを司る時計遺伝子2に関しては興味があればググっていただくとして、ここでは概日リズムの可視化に用いられる手法の1つであるアクトグラムについて解説していきます。
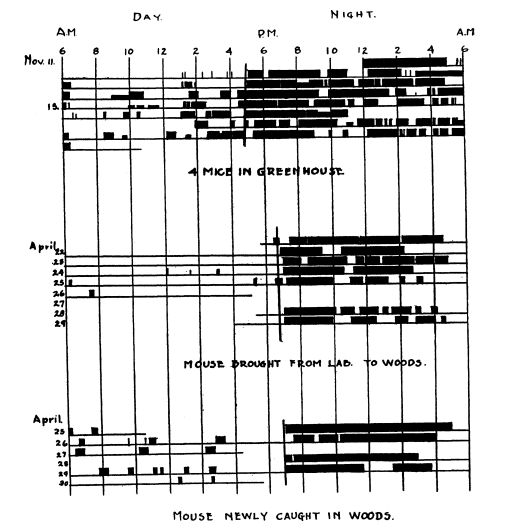
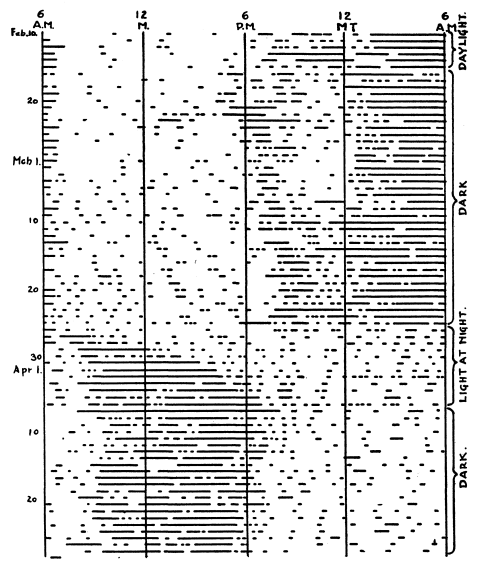
アクトグラムは1926年にメイナード ジョンソン(Maynard Johnson)によって導入されたと言われています(Refinetti et al. 2007)。彼の発明したアクトグラムという可視化手法は活動のリズムが視覚的に分かりやすいという点で優れています(図 6)。 しかし、彼の発明したアクトグラムは24時間(1日区切り)であったため、24時間を超えるリズムに気付きにくいという欠点がありました。学術的な意味合いはともかく、筆者が実現したかった昼寝や3交代制など不規則な睡眠を見切れることなく表示するには24時間の軸では足りません。
これを解決するのが、24時間のアクトグラムを2つ並べたDouble-plotted actogramで、(少なくとも筆者の調べた限り)1960年にコリン・ピッテンドリー(Colin Pittendrigh)が”Circadian Rhythms and the Circadian Organization of Living Systems”という論文(Pittendrigh 1960)で用いたものが初出だと思います(図 7)。
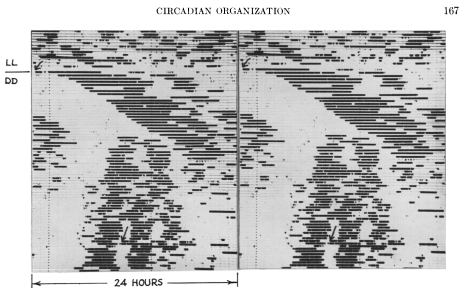
ということで、今回はダブルプロットのアクトグラムを筆者なりに改良した可視化手法で睡眠の周期を分析することにしました(図 5)。
3. 材料と方法
このJupyter Notebook(.ipynbファイル)は、Google Fitからダウンロードした睡眠データ(.json), VS Code及びPython, Jupyterの拡張機能を必要とします。Google Colabでは動作しません。また、それ以外の環境では検証していません。
VS Codeで実行することで、
- 睡眠データの分析は全てローカル環境で実行される
- 大容量のデータも扱える
- データが外部にアップロードされることがない というメリットが生まれます。
このJupyter Notebook(.ipynbファイル)はモジュール式となっているため、個別の可視化手法を必要に応じて実行することが可能です。
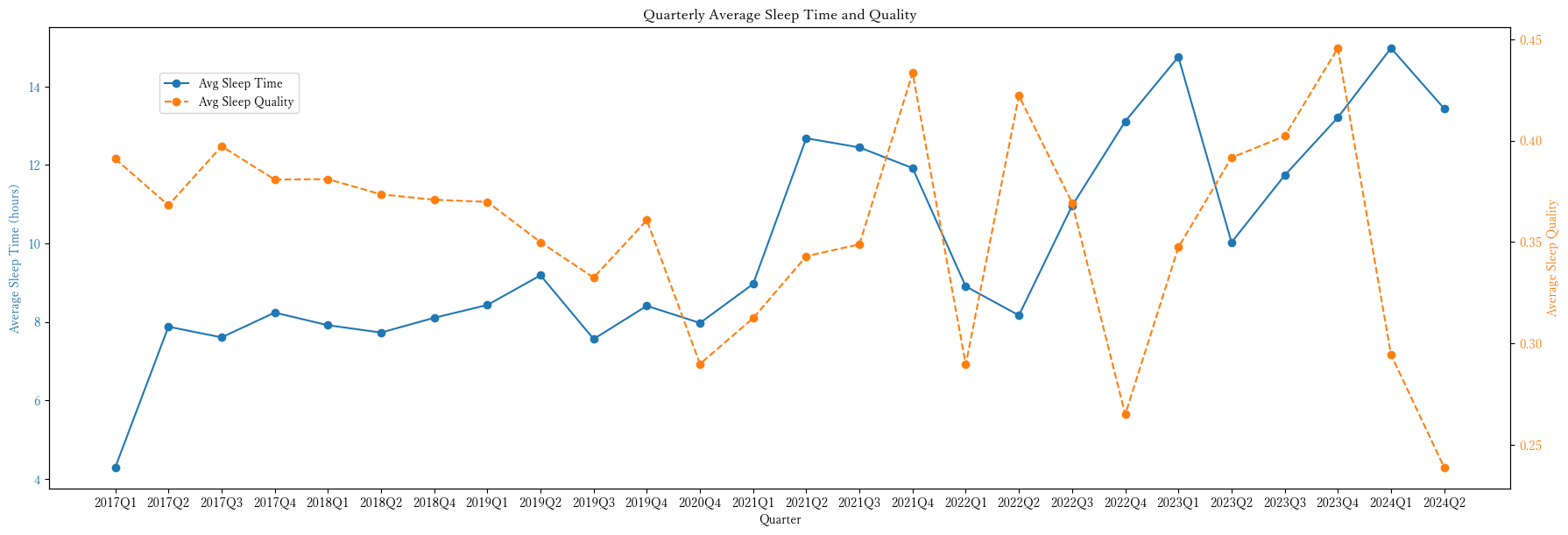
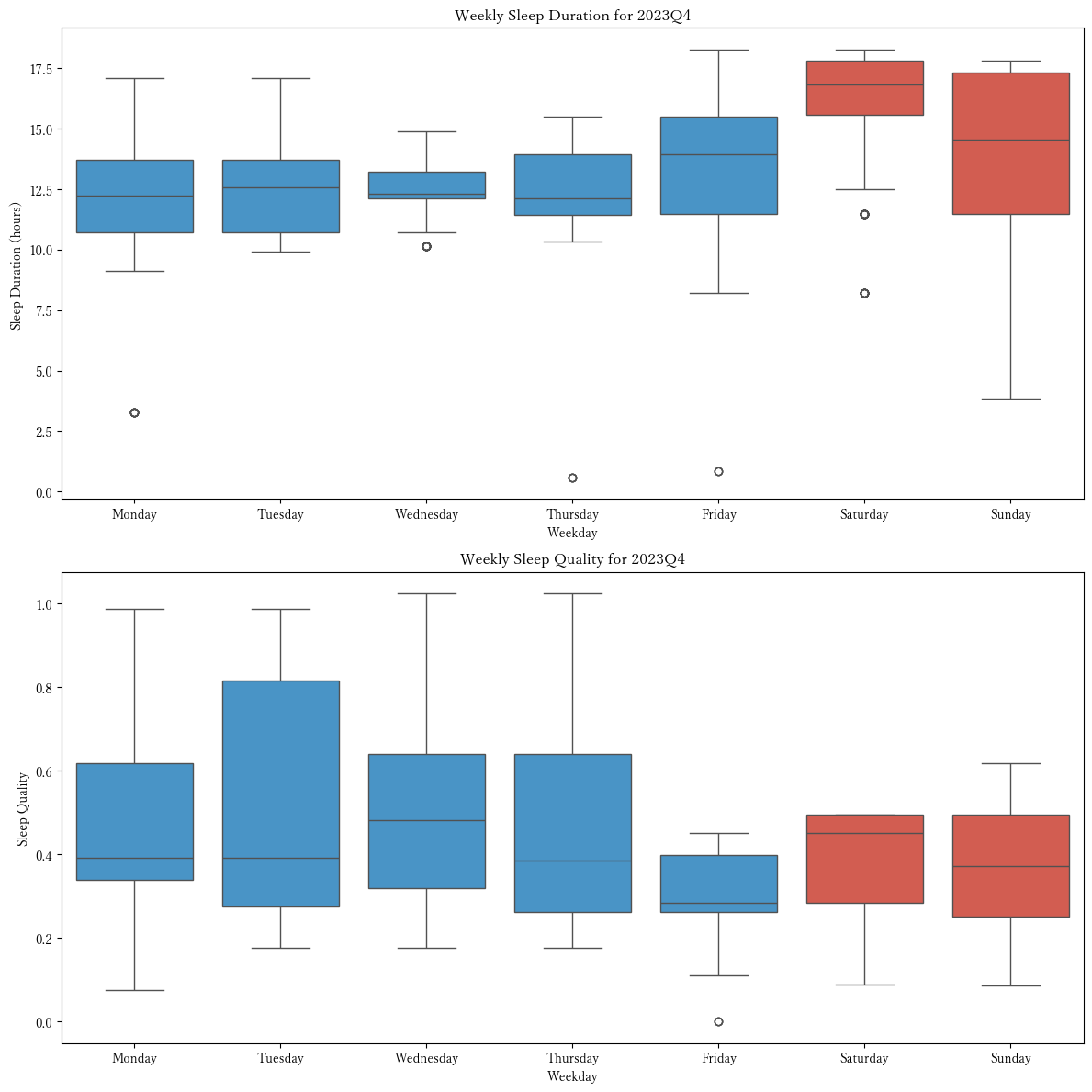
今のところ、四半期ごとのアクトグラム(図 8), 任意の期間のアクトグラム及びミッドスリープタイム(図 9), 四半期ごとの睡眠時間及び睡眠の質の推移の可視化(図 10 (a))及び四半期の範囲で曜日別の睡眠時間及び睡眠の質の可視化(図 10 (b)), 任意の日付の睡眠記録(睡眠ステージのサイクル)の可視化(図 11)が行えます。

3-1. 必要なもの
前述の通り、このJupyter Notebook(.ipynbファイル)は以下のものを必要とします。
- GitHubからダウンロードしたJupyter Notebook(
.ipynbファイル) - Google Fitからダウンロードした睡眠データ(
.jsonファイル) - VS Code(Google Colabでは実行できません)
- Python拡張機能
- Jupyter拡張機能
3-2. 実行方法
Google データ エクスポートにアクセスしGoogle Fitのデータをダウンロードした後(データのエクスポートをリクエストしてからダウンロード可能になるまで、数時間~数日かかります)、Jupyter Notebook(.ipynbファイル)を、1セルずつ順番に実行してください(Step by Stepでファイルの読み込みや期間の設定をするため 「すべてを実行」で一括して行うことはできません。)
3-2-1. Google Fit からデータをダウンロードする方法
Google データ エクスポートにアクセスします。
追加するデータの選択にて選択をすべて解除します(余計なデータが多すぎるため)。
Fit(Google Fit)のみを選択します。
一番下までスクロールし、
次のステップをクリックします。ファイル形式、エクスポート回数、エクスポート先の選択をします。
エクスポート先はダウンロードリンクをメールで送信を選択します頻度は1回エクスポートを選択しますファイル形式は.zipを選択しますファイルサイズは50GBを選択します(念の為)- 上記を確認した後、
エクスポートを作成をクリックします
データのエクスポートが処理され、ダウンロードリンクがメールで送られていくるまで数時間から数日かかります。気長に待ちます(ページを閉じても大丈夫です)。
- 進捗はGoogle データ エクスポートにて確認できます
- メールはデータのエクスポートをリクエストしたGoogleアカウント宛(gmail)に届きます
ダウンロードリンクが書かれたメールを開き、ダウンロードページに跳びます(
ファイルをダウンロードをクリックします)。- メールの件名は
Google データをダウンロードできるようになりましたでした
- メールの件名は
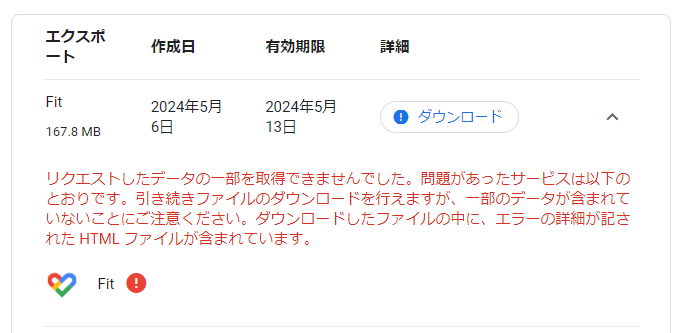
Googleアカウントのパスワードを入力後、データをダウンロードします。
- 筆者の場合、エラーが含まれていました(が、どうしようもないので続行します)
以上で、Google Fitデータのダウンロードは終了です。
3-2-2. データ分析の流れ
モジュールのインポート
データの取り込み
(手動の睡眠記録がある場合)データセットの選択
(必要であれば)データをCSVファイルとしてエクスポート
アクトグラムを用いた四半期ごとの睡眠記録の可視化

四半期ごとの統計
任意の日付の睡眠記録の可視化
3-2-2-1. モジュールのインポート
以下のセルを実行し、(もしそのモジュールがない場合、自動で)必要なモジュールをインポートします。
import subprocess
import sys
# 必要なライブラリをリストにまとめる
required_libraries = [
'json',
'pandas',
'matplotlib',
'pytz',
'ipywidgets',
'numpy',
'seaborn',
'ipyfilechooser',
'plotly'
]
# ライブラリのインストール関数
def install_and_import(library):
try:
__import__(library)
except ImportError:
subprocess.check_call([sys.executable, "-m", "pip", "install", library])
__import__(library)
# 各ライブラリのインストールとインポート
for library in required_libraries:
install_and_import(library)
# インポート文
import json
import pandas as pd
import os
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Yu Mincho', #'Hiragino Kaku Gothic ProN', #'Meiryo', #'Noto Sans CJK JP'
import matplotlib.dates as mdates
import pytz
import ipywidgets as widgets
import numpy as np
import seaborn as sns
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
from ipywidgets import DatePicker, Button, HBox
from matplotlib.lines import Line2D
from pytz import timezone
from IPython.display import display, clear_output
from ipyfilechooser import FileChooser
from datetime import datetime
from datetime import timedelta
print("All libraries are installed and imported successfully.")3-2-2-2. データの取り込み
以下のセルを実行し、
- データの読み込み
- データの変換 を行います。
VS Codeで実行している場合、睡眠データの分析は全てローカル環境で実行されます。 また、データが外部にアップロードされることはありませんのでご安心ください。
睡眠データの読み込み
# ファイルアップロードウィジェットの作成
uploader = widgets.FileUpload(
accept='.json', # JSONファイルのみを許可
multiple=True, # 複数のファイルをアップロード可能
description='Upload JSON files'
)
file_loading_flag = False
# アップロードされたデータを処理する関数
def process_uploaded_files(change):
global file_loading_flag
# 処理中メッセージを表示
with output:
clear_output()
print("ファイルの処理中です。次のセルには進まないでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
try:
for file_info in change['new']:
print(f"Processing {file_info['name']}")
sys.stdout.flush() # 出力を即座にフラッシュ
content = file_info['content']
import_data = json.loads(content.tobytes().decode('utf-8'))
df = load_and_process_sleep_data(import_data, 'Type of Sleep')
print("ファイルの読み込みが完了しました。次のセルに進んでください")
file_loading_flag = True
with output:
if file_loading_flag is True:
clear_output()
print("ファイルの読み込みが完了しました。次のセルに進んでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
except Exception as e:
with output:
clear_output()
print(f"エラーが発生しました: {e}")
sys.stdout.flush() # 出力を即座にフラッシュ
# JSONデータをDataFrameに変換するための関数
def load_and_process_sleep_data(import_data, type_value):
data_source = import_data['Data Source']
data_points = import_data['Data Points']
df = pd.DataFrame([{
'data_source': data_source,
'start_time_ns': dp['startTimeNanos'],
'end_time_ns': dp['endTimeNanos'],
'sleep_state': dp['fitValue'][0]['value']['intVal'],
'modified_time_ms': dp['modifiedTimeMillis'],
'Type': type_value
} for dp in data_points])
df['start_time'] = pd.to_datetime(df['start_time_ns'], unit='ns')
df['end_time'] = pd.to_datetime(df['end_time_ns'], unit='ns')
return df
# 出力ウィジェットの作成
output = widgets.Output()
# 初期メッセージの表示
with output:
print("ファイルの処理が完了するまで、次のセルには進まないでください")
# アップロードイベントに関数をバインド
uploader.observe(process_uploaded_files, names='value')
# ウィジェットの表示
display(uploader)
display(output)この際に、ファイルの読み込みが完了しました。次のセルに進んでくださいと表示されるまでは次のセルに進まないでください。
睡眠データのフォーマット関数など
def parse_datetime_with_format(dt_series):
dt_series_with_ms = dt_series[dt_series.astype(str).str.contains(r"\.\d+")]
dt_series_without_ms = dt_series[~dt_series.astype(str).str.contains(r"\.\d+")]
parsed_with_ms = pd.to_datetime(dt_series_with_ms, format='%Y-%m-%d %H:%M:%S.%f', errors='coerce')
parsed_without_ms = pd.to_datetime(dt_series_without_ms, format='%Y-%m-%d %H:%M:%S', errors='coerce')
return pd.concat([parsed_with_ms, parsed_without_ms]).sort_index()
# アップロードされたファイル名とデータの取得
uploaded_files = uploader.value3-2-2-3. 手動で記録されたデータセットの指定
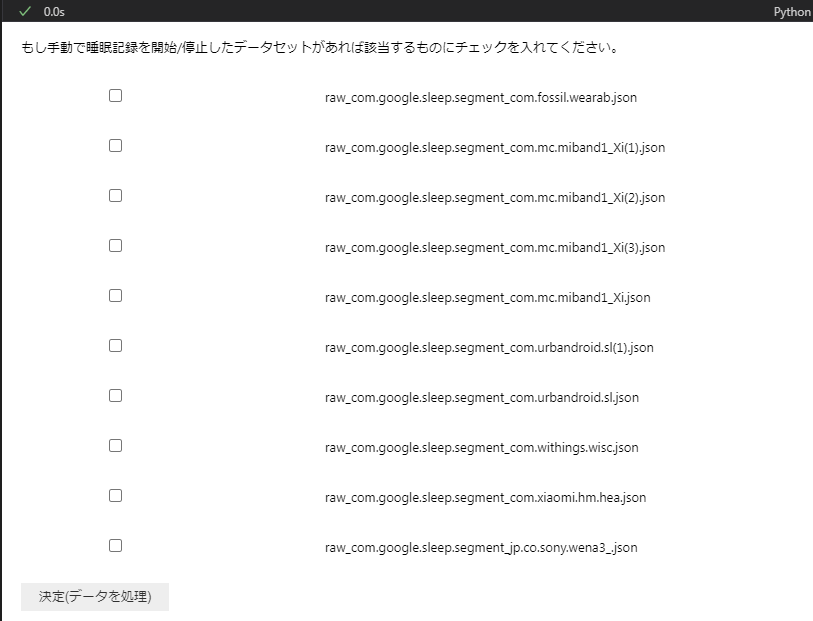
睡眠記録は、スマートウォッチや睡眠マットを使っている場合は自動で記録されますが、そうではない場合はスマートフォンのアプリ等を使って、手動で睡眠記録を開始・終了しているはずです。
手動で睡眠記録を開始・終了することで、布団(ベッド)に入った時刻が確実に分かるため、睡眠潜時(就寝してから入眠するまでにかかる時間)が算出できるため、手動・自動を区別しています。
以下のスクリプトでは、チェックボックスにチェックを入れることで、(手動で記録されたものがある場合)そのデータが手動か自動かを識別します。
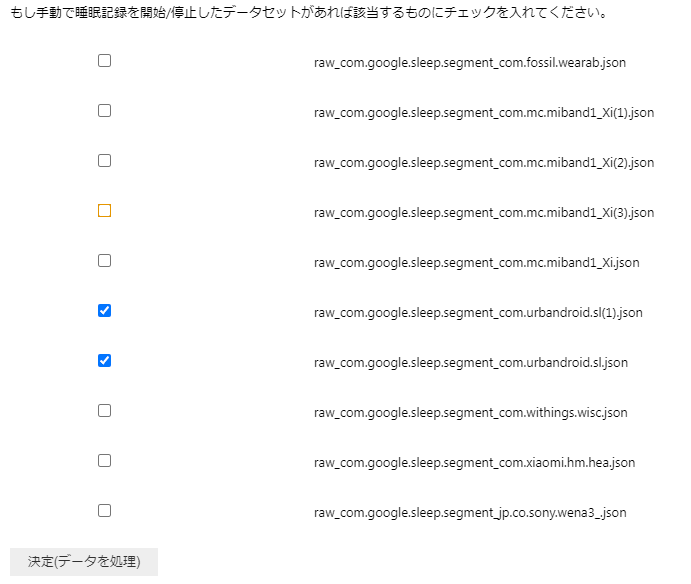
手動睡眠記録の識別
# 説明文を表示
description_label = widgets.Label('もし手動で睡眠記録を開始/停止したデータセットがあれば該当するものにチェックを入れてください。')
display(description_label)
# 空のデータフレームを初期化
combined_data = pd.DataFrame()
# ファイルと対応するチェックボックスを表示
checkboxes = []
for file_details in uploader.value:
cb = widgets.Checkbox(
value=False,
description='',
disabled=False
)
label = widgets.Label(file_details['name'])
box = widgets.HBox([cb, label])
checkboxes.append(cb)
display(box)
# プロセスボタンを作成
process_button = widgets.Button(description="決定(データを処理)")
# ボタンのイベントハンドラー
def on_button_clicked(b):
clear_output(wait=True)
global combined_data
for cb, file_details in zip(checkboxes, uploader.value):
filename = file_details['name']
content = file_details['content']
sleep_data = json.loads(content.tobytes().decode('utf-8'))
# チェックボックスの値に応じてデータタイプを設定
type_column_value = 'Manual' if cb.value else 'Auto'
data = load_and_process_sleep_data(sleep_data, type_column_value)
combined_data = pd.concat([combined_data, data], ignore_index=True)
# データ処理後の状態を表示
print("Data processing complete. Dataframe contains:", combined_data.shape[0], "rows.")
process_button.on_click(on_button_clicked)
display(process_button)3-2-2-4. データをCSVとしてエクスポート
もし、他のツール(例えばChatGPTなど)で分析を行ないたい場合、Google Fitからダウンロードしたファイル(.json形式)をそのまま用いるよりも、CSVファイルの方が便利です。
CSVファイルとしてデータをエクスポートしたい場合は、以下のセルを実行してください。Selectボタンを押して保存するフォルダを指定し、再度Selectボタンを押し、その下の✔Saveボタンを押すことで、保存が行えます。 なお、このセルは任意(オプション)のため、実行しなくても問題ありません。
CSVとしてエクスポート
# CSVを保存する関数
# ユーザーのデスクトップパスを取得
desktop_path = os.path.join(os.environ['USERPROFILE'], 'Desktop')
# CSVを保存する関数
def save_csv(sleep_data, path):
sleep_data.to_csv(path, index=False)
return f'CSVファイルを {path}に保存しました。'
# 「Save」ボタンの動作を定義
def on_save_button_clicked(b):
with output:
clear_output()
if not fc.selected:
print("CSVファイルの保存先を選択してください")
else:
# ここでDataFrameを保存
result = save_csv(sleep_data, fc.selected) # dfは保存したいDataFrameの変数名
print(result)
# ファイル選択ダイアログを設定
fc = FileChooser(desktop_path)
fc.default_filename = 'sleep_data.csv'
fc.use_dir_icons = True
# 「Save」ボタンの作成
save_button = widgets.Button(
description='Save',
button_style='',
tooltip='Click to save the CSV file',
icon='check'
)
save_button.on_click(on_save_button_clicked)
# 出力エリアを設定
output = widgets.Output()
# ウィジェットを表示
display(fc, save_button, output)CSVファイルの構造は以下の通りです。
data_source: インポートしたデータセットの名前です(基本的にはGoogle Fitから取得されたデバイスの名前です)Mid_sleep_time: 算出されたミッドスリープタイム
Type: 基本的にはAutoかManualのどちらかが入りますAuto: 自動で睡眠記録が開始・停止していることを意味しますManual: 手動で睡眠記録が開始・停止していることを意味しますOther: 算出されたミッドスリープタイムであることを意味します
in_bed_time: 手動で睡眠記録を開始している場合、その開始時刻が入りますstart_time: 各睡眠ステージが開始された時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)end_time: 各睡眠ステージが終了した時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)sleep_state: [Google Fit](https://developers.google.com/fit/scenarios/read-sleep-data?hl=ja#sleep_stage_valuesで定められた睡眠ステージの値(1~6)と、算出したミッドスリープタイム(10)が入りますsession_id: 1回の睡眠ごとに割り振られたIDです(end_timeから次のstart_timeまでの間が2時間以上離れている場合、別の睡眠とみなしています)
睡眠ステージは以下の通りです。
| 睡眠ステージのタイプ | 値 |
|---|---|
| 覚醒(睡眠サイクル中) | 1 |
| 睡眠 | 2 |
| ベッド外 | 3 |
| 浅い睡眠 | 4 |
| 深い睡眠 | 5 |
| レム睡眠 | 6 |
| ミッドスリープタイム | 10 |
(おそらくですが)睡眠ステージ2はデータの信頼性が低く使われていない傾向にあります ミッドスリープタイムはオリジナル(Google Fitのデータ)にはない項目です
3-2-2-5. アクトグラムを用いた四半期ごとの睡眠記録の可視化
以下のセルを実行することで、アクトグラムの可視化を行えます。
- JSONファイルに含まれていたデータ期間に応じて、四半期(3ヶ月)ごとにアクトグラムがプロットされます
- 1年につき4枚グラフが出るので、含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります
- 任意の期間のアクトグラムを表示することも可能です
アクトグラムの表示を準備するセル
# 日またぎを処理する関数
def adjust_end_time(start, end):
if end < start:
end += 1440 # 翌日にまたがる場合は24時間分(分)を加算
return end
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
jst_sleep_data = sleep_data.copy()
jst_sleep_data['start_time'] = convert_to_jst_if_needed(jst_sleep_data['start_time'])
jst_sleep_data['end_time'] = convert_to_jst_if_needed(jst_sleep_data['end_time'])
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
jst_sleep_data['start_time'] = jst_sleep_data['start_time'].astype('datetime64[ns, Asia/Tokyo]')
jst_sleep_data['end_time'] = jst_sleep_data['end_time'].astype('datetime64[ns, Asia/Tokyo]')
return jst_sleep_data
def plot_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {1: '#e0ffff', 2: '#b3e5fc', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10: 'yellow'}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig, ax = plt.subplots(figsize=(20, num_days * 0.4))
for _, row in filtered_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
ax.plot([row['start_minutes'], row['end_minutes']], [day_of_week, day_of_week], color=row['color'], alpha=0.7)
ax.plot([row['start_minutes'] + 1440, row['end_minutes'] + 1440], [day_of_week + 1, day_of_week + 1], color=row['color'], alpha=0.7)
ax.set_xlim(0, 2880)
ax.set_ylim(0, num_days)
ax.set_yticks(range(num_days))
ax.set_yticklabels([(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)])
ax.set_xlabel('Time')
ax.set_ylabel('Days from Start Date')
plt.title(f'Actogram from {start_date} to {end_date}')
plt.grid(True)
plt.xticks(ticks=[i * 60 for i in range(49)], labels=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)], rotation=45)
plt.show()
# データセットの範囲確認
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
start_date = jst_sleep_data['start_time'].min().strftime('%Y-%m-%d')
end_date = jst_sleep_data['start_time'].max().strftime('%Y-%m-%d')
print(f"This dataset contains data from {start_date} to {end_date}.")上記のセルを実行すると、 > This dataset contains data from YYYY-MM-DD to YYYY-MM-DD と表示されます。ここに表示される期間がデータセットに含まれていた期間です。
全てのデータを可視化する場合は、以下のセルを実行してください(このセルを飛ばし、任意の期間だけを可視化することも可能です)。
全ての期間を対象に四半期ごとにアクトグラムをプロット
# 四半期毎にデータをプロット
start_year = jst_sleep_data['start_time'].dt.year.min()
end_year = jst_sleep_data['start_time'].dt.year.max()
last_date = jst_sleep_data['start_time'].max()
for year in range(start_year, end_year + 1):
for quarter in range(1, 5):
start_month = 3 * quarter - 2
end_month = 3 * quarter
quarter_start_date = pd.Timestamp(year=year, month=start_month, day=1).tz_localize('Asia/Tokyo')
quarter_end_date = pd.Timestamp(year=year, month=end_month, day=1).tz_localize('Asia/Tokyo') + pd.DateOffset(months=1) - pd.DateOffset(days=1)
if quarter_start_date > last_date:
break # この四半期の開始日がデータセットの最後の日を超えている場合はスキップ
if quarter_end_date > last_date:
quarter_end_date = last_date # 四半期の終了日がデータセットの最後の日を超えている場合は調整
plot_actogram(jst_sleep_data, quarter_start_date.strftime('%Y-%m-%d'), quarter_end_date.strftime('%Y-%m-%d'))任意の期間を選択し、可視化したい場合は以下のセルを実行してください。
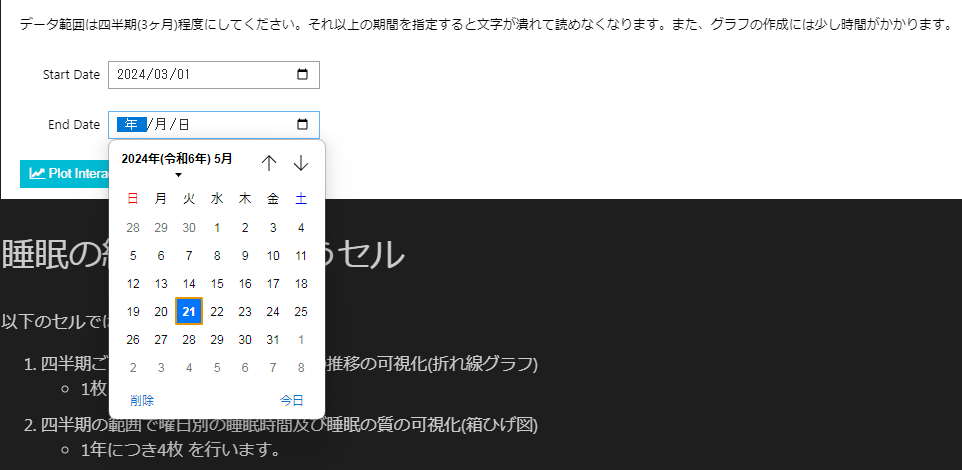
- 以下のセルを実行することで、任意の期間に絞ったアクトグラムをブラウザ上に表示できます
- データの期間は四半期(3ヶ月)を推奨しています
- 四半期より長い期間を選択した場合、Y軸の文字が潰れてしまいます
- このセルでは、ミッドスリープタイムも併せて表示しています
- このセルを実行しなくても問題はありません
任意の期間に絞ったアクトグラムのプロット
# 任意の期間のアクトグラム
def plot_interactive_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {
1: '#e0ffff', # 覚醒(睡眠サイクル中)
2: '#b3e5fc', # 睡眠
3: '#ff5252', # ベッド外
4: '#03a9f4', # 浅い睡眠
5: '#303f9f', # 深い睡眠
6: '#ab47bc', # レム睡眠
10: 'black' # ミッドスリープタイム(色を強調)
}
sleep_stage_labels = {
1: '覚醒(睡眠サイクル中)',
2: '睡眠',
3: 'ベッド外',
4: '浅い睡眠',
5: '深い睡眠',
6: 'レム睡眠',
10: 'ミッドスリープタイム'
}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig = go.Figure()
for sleep_state, color in color_map.items():
sleep_state_data = filtered_data[filtered_data['sleep_state'] == sleep_state]
if not sleep_state_data.empty:
for _, row in sleep_state_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
line_width = 7.5 if sleep_state == 10 else 5 # ミッドスリープタイムの場合は線の太さを15に設定
y_offset = 0 if sleep_state == 10 else 0 # ミッドスリープタイムの場合はy座標をさらにオフセット
opacity = 1 if sleep_state == 10 else 0.5 # ミッドスリープタイム以外は透明度を0.3に設定
fig.add_trace(go.Scatter(
x=[row['start_minutes'], row['end_minutes']],
y=[day_of_week + y_offset, day_of_week + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
fig.add_trace(go.Scatter(
x=[row['start_minutes'] + 1440, row['end_minutes'] + 1440],
y=[day_of_week + 1 + y_offset, day_of_week + 1 + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
# 凡例を統合
unique_labels = set()
fig.for_each_trace(lambda trace: trace.update(showlegend=False) if trace.name in unique_labels else unique_labels.add(trace.name))
fig.update_layout(
title=f'Interactive Actogram from {start_date} to {end_date}',
xaxis_title='Time',
yaxis_title='Days from Start Date',
xaxis=dict(
tickmode='array',
tickvals=[i * 60 for i in range(49)],
ticktext=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)],
range=[0, 2880]
),
yaxis=dict(
tickvals=list(range(num_days)),
ticktext=[(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)],
range=[0, num_days],
tickfont=dict(size=10) # Y軸ラベルの文字サイズを小さく
),
hovermode='closest',
legend=dict(
itemsizing='constant'
)
)
pio.write_html(fig, file='sleep_data_plot.html', auto_open=True)
# ウィジェットの作成
start_date_picker = widgets.DatePicker(
description='Start Date',
disabled=False
)
end_date_picker = widgets.DatePicker(
description='End Date',
disabled=False
)
interactive_button = widgets.Button(
description='Plot Interactive Actogram',
button_style='info',
tooltip='Click to plot the interactive actogram',
icon='line-chart'
)
notice_label = widgets.Label(
value='データ範囲は四半期(3ヶ月)程度にしてください。それ以上の期間を指定すると文字が潰れて読めなくなります。また、グラフの作成には少し時間がかかります。'
)
# ボタンがクリックされたときの動作
def on_button_clicked(b):
start_date = start_date_picker.value
end_date = end_date_picker.value
if start_date is not None and end_date is not None:
plot_interactive_actogram(sleep_data, start_date, end_date)
else:
print("Please select both start and end dates.")
interactive_button.on_click(on_button_clicked)
# ウィジェットの表示
display(notice_label, start_date_picker, end_date_picker, interactive_button)3-2-2-6. 睡眠の統計分析
以下のセルでは、
- 四半期ごとの睡眠時間及び睡眠の質の推移の可視化(折れ線グラフ)
- 1枚
- 四半期の範囲で曜日別の睡眠時間及び睡眠の質の可視化(箱ひげ図)
- 1年につき4枚 を行います。
含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります。 そのため、実行せず次のセルに進んでも構いません。
睡眠の統計
def calculate_sleep_quality(sleep_data):
# 各セッションの睡眠時間を計算
session_start_end = sleep_data.groupby('session_id').agg(
start_time=('start_time', 'min'),
end_time=('end_time', 'max')
).reset_index()
session_start_end['sleep_duration_total'] = (session_start_end['end_time'] - session_start_end['start_time']).dt.total_seconds() / 3600
# 深い睡眠の割合を計算
sleep_data['sleep_duration'] = (sleep_data['end_time'] - sleep_data['start_time']).dt.total_seconds() / 3600
deep_sleep_data = sleep_data[sleep_data['sleep_state'] == 5] # 深い睡眠
deep_sleep_duration = deep_sleep_data.groupby('session_id')['sleep_duration'].sum().reset_index()
# 列名を変更
deep_sleep_duration.rename(columns={'sleep_duration': 'sleep_duration_deep'}, inplace=True)
sleep_quality = pd.merge(session_start_end, deep_sleep_duration, on='session_id', how='left')
sleep_quality['sleep_quality'] = sleep_quality['sleep_duration_deep'].fillna(0) / sleep_quality['sleep_duration_total']
return sleep_quality[['session_id', 'sleep_duration_total', 'sleep_quality']]
def calculate_quarterly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
quarterly_stats = sleep_data.groupby('quarter').agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return quarterly_stats
def plot_quarterly_sleep_stats(quarterly_stats):
fig, ax1 = plt.subplots(figsize=(18, 6))
ax1.set_xlabel('Quarter')
ax1.set_ylabel('Average Sleep Time (hours)', color='tab:blue')
ax1.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_time'], color='tab:blue', marker='o', label='Avg Sleep Time')
ax1.tick_params(axis='y', labelcolor='tab:blue')
ax2 = ax1.twinx()
ax2.set_ylabel('Average Sleep Quality', color='tab:orange')
ax2.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_quality'], color='tab:orange', marker='o', linestyle='--', label='Avg Sleep Quality')
ax2.tick_params(axis='y', labelcolor='tab:orange')
fig.tight_layout()
fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9))
plt.title('Quarterly Average Sleep Time and Quality')
plt.show()
def calculate_weekly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekly_stats = sleep_data.groupby(['quarter', 'weekday']).agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return weekly_stats
def plot_weekly_sleep_stats_boxplot(sleep_data_jst):
sleep_quality = calculate_sleep_quality(sleep_data_jst)
sleep_data = pd.merge(sleep_data_jst, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_colors = ['#3498db', '#3498db', '#3498db', '#3498db', '#3498db', '#e74c3c', '#e74c3c'] # 平日は青、土日は赤
weekday_palette = dict(zip(weekdays, weekday_colors))
for quarter in sleep_data['quarter'].unique():
quarter_data = sleep_data[sleep_data['quarter'] == quarter]
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12))
# 睡眠時間の箱ひげ図
sns.boxplot(x='weekday', y='sleep_duration_total', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax1, hue='weekday', dodge=False)
ax1.set_title(f'Weekly Sleep Duration for {quarter}')
ax1.set_xlabel('Weekday')
ax1.set_ylabel('Sleep Duration (hours)')
ax1.legend([],[], frameon=False) # レジェンドを非表示にする
# 睡眠の質の箱ひげ図
sns.boxplot(x='weekday', y='sleep_quality', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax2, hue='weekday', dodge=False)
ax2.set_title(f'Weekly Sleep Quality for {quarter}')
ax2.set_xlabel('Weekday')
ax2.set_ylabel('Sleep Quality')
ax2.legend([],[], frameon=False) # レジェンドを非表示にする
plt.tight_layout()
plt.show()
# データの準備
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
# 四半期ごとの統計を計算
quarterly_stats = calculate_quarterly_sleep_stats(sleep_data_jst)
# 結果をプロット
plot_quarterly_sleep_stats(quarterly_stats)
# 曜日別の統計を計算
weekly_stats = calculate_weekly_sleep_stats(sleep_data_jst)
# 結果を箱ひげ図でプロット
plot_weekly_sleep_stats_boxplot(sleep_data_jst)3-2-2-7. 任意の日付の睡眠記録の可視化
以下のセルを実行することで、ユーザーが指定した日付の睡眠セッション分析し、睡眠ステージの推移をグラフに表示することができます。
任意の日付の睡眠記録の可視化
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
sleep_data_jst = sleep_data.copy()
sleep_data_jst['start_time'] = convert_to_jst_if_needed(sleep_data_jst['start_time'])
sleep_data_jst['end_time'] = convert_to_jst_if_needed(sleep_data_jst['end_time'])
if 'in_bed_time' in sleep_data.columns:
sleep_data_jst['in_bed_time'] = convert_to_jst_if_needed(sleep_data_jst['in_bed_time'])
else:
sleep_data_jst['in_bed_time'] = None
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
sleep_data_jst['start_time'] = sleep_data_jst['start_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['end_time'] = sleep_data_jst['end_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['in_bed_time'] = sleep_data_jst['in_bed_time'].astype('datetime64[ns, Asia/Tokyo]')
return sleep_data_jst
def create_session_data(sleep_data_jst):
# 各セッションの最終 'end_time' を取得して日付に変換
session_dates = sleep_data_jst.groupby('session_id')['end_time'].max().dt.date
session_dates = session_dates.reset_index()
session_dates.rename(columns={'end_time': 'session_date'}, inplace=True)
# 睡眠時間と睡眠潜時の計算
sleep_times = sleep_data_jst.groupby('session_id').agg(
sleep_time=('end_time', lambda x: (x.max() - x.min()).total_seconds() / 3600),
start_time=('start_time', 'min')
)
sleep_times.reset_index(inplace=True)
# 睡眠潜時の計算
sleep_latency = sleep_data_jst.groupby('session_id').apply(
lambda group: calculate_sleep_latency(group[['in_bed_time', 'start_time', 'Type', 'sleep_state']]),
include_groups=False # 追加: グループ化列を適用操作から除外
).reset_index(name='sleep_latency')
# 結合して全データを含むデータフレームを作成
full_session_data = pd.merge(session_dates, sleep_times[['session_id', 'sleep_time']], on='session_id')
full_session_data = pd.merge(full_session_data, sleep_latency, on='session_id')
return full_session_data
def calculate_sleep_latency(group):
group = group.sort_values(by='start_time')
auto_sleep_times = group[(group['Type'] == 'Auto') & (group['sleep_state'] >= 4)]
if not auto_sleep_times.empty:
auto_sleep_time = auto_sleep_times['start_time'].iloc[0]
if pd.notna(group['in_bed_time'].iloc[0]) and group['in_bed_time'].iloc[0] <= group['start_time'].iloc[0]:
return (auto_sleep_time - group['in_bed_time'].iloc[0]).total_seconds() / 60
return np.nan
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
full_session_data = create_session_data(sleep_data_jst)
# 日付選択ウィジェット
date_picker = DatePicker(description='Select Date', disabled=False)
def on_prev_clicked(b):
date_picker.value = date_picker.value - pd.Timedelta(days=1) if date_picker.value else None
def on_next_clicked(b):
date_picker.value = date_picker.value + pd.Timedelta(days=1) if date_picker.value else None
button_prev = Button(description="Previous Day")
button_next = Button(description="Next Day")
button_prev.on_click(on_prev_clicked)
button_next.on_click(on_next_clicked)
display(HBox([button_prev, button_next]))
display(date_picker)
# タイムゾーンを確認して適切に日付を表示する関数
def set_plot_title(ax, session_id, sleep_data_jst):
jst = pytz.timezone('Asia/Tokyo')
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
if session_data['start_time'].dt.tz:
start_time_jst = session_data['start_time'].min().astimezone(jst)
end_time_jst = session_data['end_time'].max().astimezone(jst)
else:
start_time_utc = session_data['start_time'].min().replace(tzinfo=pytz.utc)
end_time_utc = session_data['end_time'].max().replace(tzinfo=pytz.utc)
start_time_jst = start_time_utc.astimezone(jst)
end_time_jst = end_time_utc.astimezone(jst)
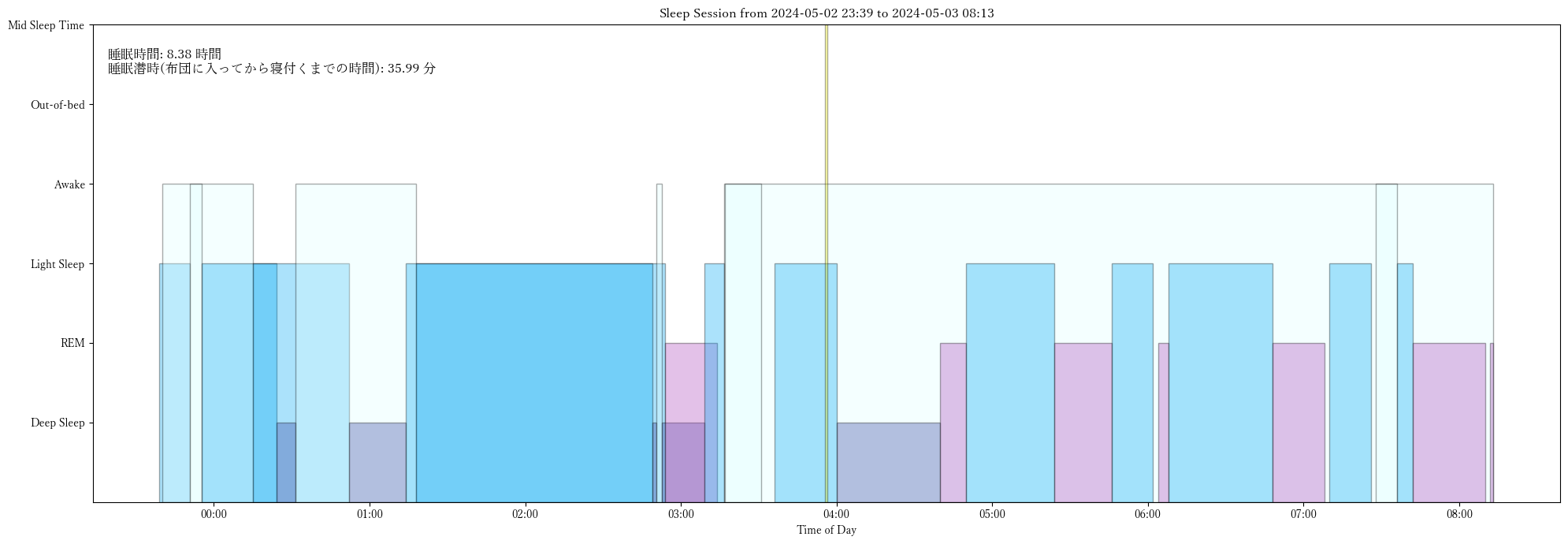
title = f"Sleep Session from {start_time_jst.strftime('%Y-%m-%d %H:%M')} to {end_time_jst.strftime('%Y-%m-%d %H:%M')}"
ax.set_title(title)
else:
ax.set_title("No data available for this session")
# キャプションを追加する関数
def add_caption(ax, session_id, full_session_data):
record = full_session_data[full_session_data['session_id'] == session_id].iloc[0]
# キャプションの初期部分
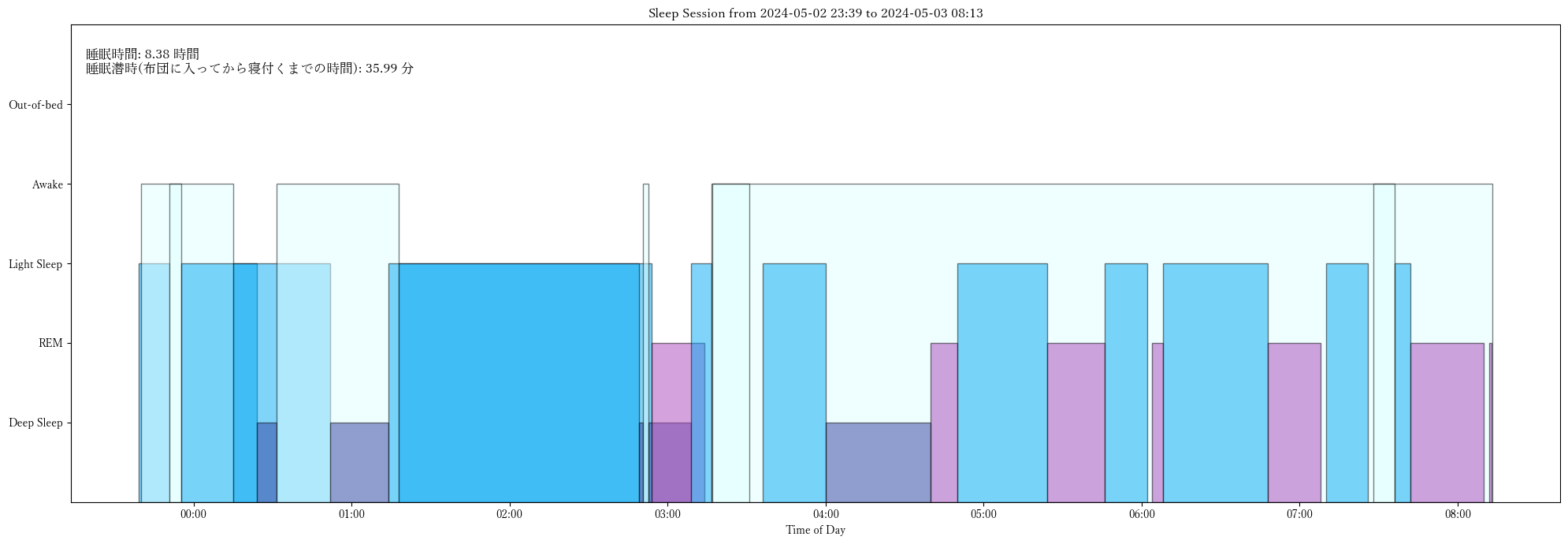
caption = f"睡眠時間: {record['sleep_time']:.2f} 時間\n"
# sleep_latencyがNaNやマイナスでない場合のみ追加
if pd.notna(record['sleep_latency']) and record['sleep_latency'] >= 0:
caption += f"睡眠潜時(布団に入ってから寝付くまでの時間): {record['sleep_latency']:.2f} 分"
ax.text(0.01, 0.95, caption, transform=ax.transAxes, fontsize=12, verticalalignment='top')
# 睡眠データをプロットする関数
def plot_sleep_data(session_id, sleep_data_jst, full_session_data):
session_info = full_session_data[full_session_data['session_id'] == session_id]
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
# 日時データのタイムゾーンを確認し、日本時間に設定
if session_data['start_time'].dt.tz is None:
session_data['start_time'] = session_data['start_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
if session_data['end_time'].dt.tz is None:
session_data['end_time'] = session_data['end_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
fig, ax = plt.subplots(figsize=(20, 7))
stage_height = {3: 5, 1: 4, 4: 3, 6: 2, 5: 1, 10: 6}
stage_colors = {1: '#e0ffff', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10:'yellow'}
data_sources = session_data['data_source'].unique()
source_count = len(data_sources)
alpha_value = 1 / source_count if source_count > 0 else 1
# プロットの時間を日本時間に合わせて設定
for index, row in session_data.iterrows():
start_pos = mdates.date2num(row['start_time'])
duration = mdates.date2num(row['end_time']) - start_pos
ax.bar(x=start_pos, height=stage_height[row['sleep_state']], width=duration,
color=stage_colors.get(row['sleep_state'], '#FFFFFF'), edgecolor='black',
align='edge', alpha=alpha_value)
ax.xaxis_date(tz=timezone('Asia/Tokyo'))
ax.xaxis.set_major_locator(mdates.HourLocator(interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M', tz=timezone('Asia/Tokyo')))
ax.set_ylim(0, 6)
ax.set_yticks([1, 2, 3, 4, 5, 6])
ax.set_yticklabels(['Deep Sleep', 'REM', 'Light Sleep', 'Awake', 'Out-of-bed', 'Mid Sleep Time'])
ax.set_xlabel('Time of Day')
set_plot_title(ax, session_id, sleep_data_jst)
add_caption(ax, session_id, session_info)
plt.tight_layout()
plt.show()
else:
print("No sleep data available for this session.")
# 日付変更時のイベントハンドラ
def on_date_change(change):
if change['new'] is not None:
selected_date = pd.to_datetime(change['new']).date()
session_id = next((sid for sid, date in full_session_data.set_index('session_id')['session_date'].items() if date == selected_date), None)
if session_id is not None:
plot_sleep_data(session_id, sleep_data_jst, full_session_data)
else:
print("No sessions found for this date.")
date_picker.observe(on_date_change, names='value')4. 課題と展望
複数デバイスからのデータを元に可視化や統計を行う際、現状ではそれぞれのデータを等価であると仮定していますが、実際には精度の低いデータセット(デバイス)が存在しています。
データの読み込みはユーザーに任せているので、そもそも精度の低いデータは読み込まなければいいだけの話なのですが、可視化してみて初めて精度の低さに気付くということもあるかと思います。せっかくモジュール式の仕組みを採用しているのだから、最初の可視化で得た気付き(このデバイスはダメそうといった判断)をフィードバックできればいいなぁと考えています。
もう1つ大きな課題として、特定の日の睡眠サイクルを可視化する際に、昼寝が可視化できないというのがあります。アクトグラムを使った睡眠リズムの可視化の際には昼寝がちゃんと可視化されているのに、その詳細は分からないというのは超ベリーバッドです。なんとかしたいです。
今後の展望としては、上記の課題の他に、英語と日本以外のタイムゾーンへの対応, 統計及びその可視化の見直し, ミッドスリープタイムの(アクトグラム以外の)可視化などを考えています。 また、睡眠に関する論文を漁り、何を可視化しどのように分析をすべきかをちゃんと勉強したいです。
4-1. 課題
- 統計や可視化の際に、対象とするデータセットを選べない
- チェックボックス等で使用するデータセットを選べるようにする
- 特定の日付の睡眠サイクルを可視化する際に、昼寝が可視化されない
- メインの睡眠に昼寝を統合してしまうとスケールが狂うので、現在の日付単位でのセレクト(
前日・翌日)から、睡眠単位のセレクト(前の睡眠・次の睡眠)へと切り替える
- メインの睡眠に昼寝を統合してしまうとスケールが狂うので、現在の日付単位でのセレクト(
- 特定の日付の睡眠サイクルを可視化する際に、睡眠データが存在しない日も選択画面(カレンダー)に表示されてしまう
- 睡眠データが存在しない日をカレンダーに表示しない・もしくは選べないようにする
- 任意の期間のアクトグラムを表示する際に、ミッドスリープタイムが1回の睡眠で2回以上表示されることがある
- 原因を詳しく調査し、ミッドスリープタイムの算出方法がおかしいのか、表示方法がおかしいのか、確かめ改善する
- ユーザーのタイムゾーンが日本時間であると仮定し分析や可視化を行っており、ユーザーがタイムゾーンを選べない(日本時間を強制している)
- タイムゾーンの変換スクリプトを見直し、決め打ちではなくユーザーが選べるようにする
- なんなら、現在、タイムゾーンの変換時をそれぞれの可視化関数で行っているのでこれをどうにかしたい
- タイムゾーンの変換も様々な書き方で行っているため、置換が効かない
- タイムゾーンの変換スクリプトを見直し、決め打ちではなくユーザーが選べるようにする
4-2. 展望
- 英語への対応
- 任意のタイムゾーンを選べるようにする
- 統計方法の見直し
- 可視化手法の見直し
- ミッドスリープタイムの可視化
- Health Connect APIへの対応
5. 感想
- 疲れました。
- PythonもJupyter Notebookも初心者かつ苦手意識がある中でなんとか世に公開できるものが出来たのは、ChatGPT-4(及び途中からGPT-4o)とClaude 3 Opusのおかげです。メインはGPT-4oでしたが、スクリプトのエラーが解決しない時はGPT-4に切り替えて、それでも解決しない時はClaude 3 Opusを使いました。Claude 3 Opusの方が解決力が高いようで、今のところClaude 3 Opusで解決できずにChatGPT-4系が解決できたという問題はありませんでした。
- ChatGPT-4とやりとりしているうちに、どんな関数があれば良くて、引数は多分こんな感じで戻り値に何が欲しくてといった仕様が見えてきたので、それをまるっと伝えるといい感じに書いてくれたのが良かったです。
- とりあえず、最初に要望を伝え企画書・仕様書を作らせ、それを元に雛形を作ってもらい、自分で必要な関数を考え、それを書いてもらうという流れでやればいいという発見を得たのが収穫でした。
- 恥ずかしながら、Git(及びGitHub)に対する知識がなく、バージョン管理がめちゃくちゃになってしまいました。ちゃんと勉強したいと思いました。
- 4月25日にこのプロジェクトを立ち上げ、Jupyter Notebookを完成させるまでに73時間, この記事を書いたり(論文漁ったり)GitHubに公開する準備をしたりするのに20時間くらいかかりました。4月から正真正銘のニートになったので、時間はいくらでもあったとは言え、ちょっとかけすぎたと感じています。あと右手の小指とその筋がとても痛くなりました。多分腱鞘炎です。
- 抗うつ薬が切れた後は起きていたくないので、18時くらいに就寝をして7時くらいに起きるという限界生活をしているのですが、それを図 8や図 9で晒すことになってしまい読者の方にドン引かれてないか心配です。そもそも読者がいるのか怪しいですが。
- 疲れました。
6. 付録
以下に、Jupyter Notebook(.ipynb)ファイルを貼ります。
Sleep Analyze Jupyter Notebook
このスクリプトはGitHubからダウンロードできます。
はじめに
- このノートブックでは、Google Fitのデータを元に睡眠データを分析します
- Google Fitからデータをダウンロードしてください
- Google Fitからデータをダウンロードする方法が分からない方は以下のドキュメント(Google Fitからデータをダウンロードする方法)をご覧ください。
- このノートブックは、筆者のような複数のデバイスを使って睡眠記録をつけている方でも問題なく分析が行えます
- セルは一括で実行せず、1つずつ実行してください
データ分析の流れ
モジュールのインポート
データの取り込み
(手動の睡眠記録がある場合)データセットの選択
(必要であれば)データをCSVファイルとしてエクスポート
アクトグラムを用いた四半期ごとの睡眠記録の可視化
四半期ごとの統計
任意の日付の睡眠記録の可視化
睡眠データの選択
GoogleからダウンロードしたZipファイルを解凍します。
takeout-YYYYMMDDxxxxxx.zipのような名前のZipファイルです
Takeout>Fit>すべてのデータの中にraw_com.google.sleep.segmentという文字列を含むJSONファイルがあるはずなので、それらをすべて任意のフォルダーにコピーします。raw_com.google.sleep.segmentをフォルダ内検索すると便利です
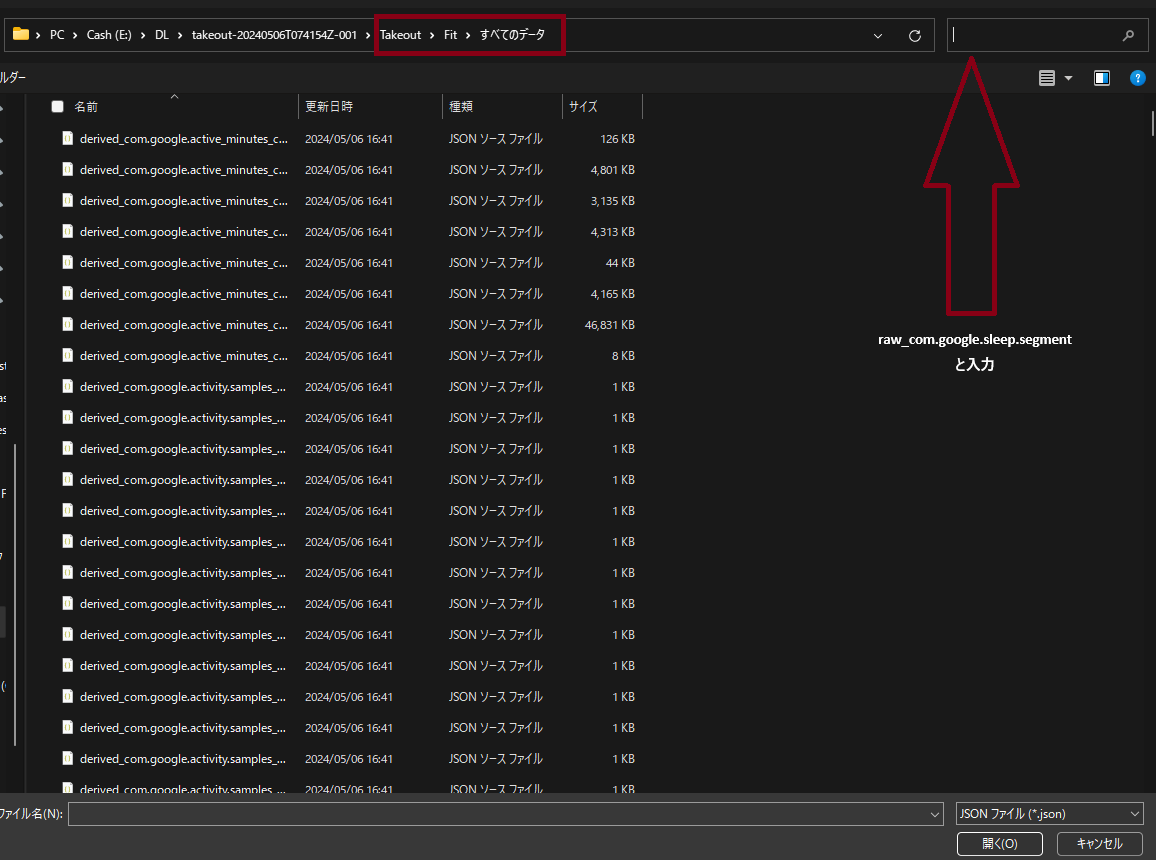
任意のフォルダーにある、全ての睡眠データ(
raw_com.google.sleep.segment)を以下のセルで読み込みます。- あるいは直接、解凍したtakeoutファイルから、
Takeout>Fit>すべてのデータと進み、raw_com.google.sleep.segmentという文字列を含むJSONファイルを選択します(フォルダ内検索を推奨します)
- あるいは直接、解凍したtakeoutファイルから、
# ファイルアップロードウィジェットの作成
uploader = widgets.FileUpload(
accept='.json', # JSONファイルのみを許可
multiple=True, # 複数のファイルをアップロード可能
description='Upload JSON files'
)
file_loading_flag = False
# アップロードされたデータを処理する関数
def process_uploaded_files(change):
global file_loading_flag
# 処理中メッセージを表示
with output:
clear_output()
print("ファイルの処理中です。次のセルには進まないでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
try:
for file_info in change['new']:
print(f"Processing {file_info['name']}")
sys.stdout.flush() # 出力を即座にフラッシュ
content = file_info['content']
import_data = json.loads(content.tobytes().decode('utf-8'))
df = load_and_process_sleep_data(import_data, 'Type of Sleep')
print("ファイルの読み込みが完了しました。次のセルに進んでください")
file_loading_flag = True
with output:
if file_loading_flag is True:
clear_output()
print("ファイルの読み込みが完了しました。次のセルに進んでください。")
sys.stdout.flush() # 出力を即座にフラッシュ
except Exception as e:
with output:
clear_output()
print(f"エラーが発生しました: {e}")
sys.stdout.flush() # 出力を即座にフラッシュ
# JSONデータをDataFrameに変換するための関数
def load_and_process_sleep_data(import_data, type_value):
data_source = import_data['Data Source']
data_points = import_data['Data Points']
df = pd.DataFrame([{
'data_source': data_source,
'start_time_ns': dp['startTimeNanos'],
'end_time_ns': dp['endTimeNanos'],
'sleep_state': dp['fitValue'][0]['value']['intVal'],
'modified_time_ms': dp['modifiedTimeMillis'],
'Type': type_value
} for dp in data_points])
df['start_time'] = pd.to_datetime(df['start_time_ns'], unit='ns')
df['end_time'] = pd.to_datetime(df['end_time_ns'], unit='ns')
return df
# 出力ウィジェットの作成
output = widgets.Output()
# 初期メッセージの表示
with output:
print("ファイルの処理が完了するまで、次のセルには進まないでください")
# アップロードイベントに関数をバインド
uploader.observe(process_uploaded_files, names='value')
# ウィジェットの表示
display(uploader)
display(output)
def parse_datetime_with_format(dt_series):
dt_series_with_ms = dt_series[dt_series.astype(str).str.contains(r"\.\d+")]
dt_series_without_ms = dt_series[~dt_series.astype(str).str.contains(r"\.\d+")]
parsed_with_ms = pd.to_datetime(dt_series_with_ms, format='%Y-%m-%d %H:%M:%S.%f', errors='coerce')
parsed_without_ms = pd.to_datetime(dt_series_without_ms, format='%Y-%m-%d %H:%M:%S', errors='coerce')
return pd.concat([parsed_with_ms, parsed_without_ms]).sort_index()
# アップロードされたファイル名とデータの取得
uploaded_files = uploader.value手動睡眠記録の選択
- 睡眠記録には、自動で睡眠を検知するタイプ(主にスマートウォッチや睡眠マットなど)のものと、スマートフォンアプリなどを用いて手動で睡眠記録の開始・停止をするものの2種類があります
- (このノートブックは、両者に対応しているだけでなく、複数のデバイスを用いて睡眠記録をつけている場合でも問題なく分析を行うことができます)
- もし、手動で睡眠記録を開始・停止している場合、以下のセルでその睡眠データにチェックを入れてください
- (よく分からない場合は特に何もせず、「決定(データを処理)」ボタンを押してください)
# 説明文を表示
description_label = widgets.Label('もし手動で睡眠記録を開始/停止したデータセットがあれば該当するものにチェックを入れてください。')
display(description_label)
# 空のデータフレームを初期化
combined_data = pd.DataFrame()
# ファイルと対応するチェックボックスを表示
checkboxes = []
for file_details in uploader.value:
cb = widgets.Checkbox(
value=False,
description='',
disabled=False
)
label = widgets.Label(file_details['name'])
box = widgets.HBox([cb, label])
checkboxes.append(cb)
display(box)
# プロセスボタンを作成
process_button = widgets.Button(description="決定(データを処理)")
# ボタンのイベントハンドラー
def on_button_clicked(b):
clear_output(wait=True)
global combined_data
for cb, file_details in zip(checkboxes, uploader.value):
filename = file_details['name']
content = file_details['content']
sleep_data = json.loads(content.tobytes().decode('utf-8'))
# チェックボックスの値に応じてデータタイプを設定
type_column_value = 'Manual' if cb.value else 'Auto'
data = load_and_process_sleep_data(sleep_data, type_column_value)
combined_data = pd.concat([combined_data, data], ignore_index=True)
# データ処理後の状態を表示
print("Data processing complete. Dataframe contains:", combined_data.shape[0], "rows.")
process_button.on_click(on_button_clicked)
display(process_button)
# 日時データの解析
combined_data['start_time'] = parse_datetime_with_format(combined_data['start_time'])
combined_data['end_time'] = parse_datetime_with_format(combined_data['end_time'])
# データを時系列順にソート
combined_data = combined_data.sort_values(by='start_time')
# 各睡眠データポイントの次の開始時刻を計算
combined_data['next_start_time'] = combined_data['start_time'].shift(-1)
# ギャップを計算(分単位)
combined_data['gap'] = (combined_data['next_start_time'] - combined_data['end_time']).dt.total_seconds() / 60
# 新しいセッションの開始を示すフラグを設定(ギャップが120分以上の場合)
combined_data['new_session_flag'] = (combined_data['gap'] > 119).astype(int)
# session_idを累積和で割り当て
combined_data['session_id'] = combined_data['new_session_flag'].shift(1).fillna(0).cumsum().astype(int)
# 'Type'が'Manual'のデータを抽出して、各セッションの最初のstart_timeをin_bed_timeとして定義
manual_sleep_data = combined_data[combined_data['Type'] == 'Manual']
in_bed_times = manual_sleep_data.groupby('session_id').first().reset_index()
in_bed_times = in_bed_times[['session_id', 'start_time']]
in_bed_times.rename(columns={'start_time': 'in_bed_time'}, inplace=True)
# 全データにin_bed_timeをマージ
combined_data = combined_data.merge(in_bed_times, on='session_id', how='left')
# Extract relevant columns: 'in_bed_time', 'expanded_start_time', 'expanded_end_time', 'majority_sleep_state'
selected_columns_data = combined_data[['data_source', 'Type', 'in_bed_time', 'start_time', 'end_time', 'sleep_state', 'session_id']]
# DataFrameを直接次のステップで使用
sleep_data = selected_columns_data # これが分析や可視化に使われるデータフレーム
# 各セッションの最初のstart_timeと最後のend_timeを取得
session_start_end = combined_data.groupby('session_id').agg({'start_time': 'first', 'end_time': 'last'}).reset_index()
# ミッドスリープタイムを計算
session_start_end['mid_sleep_time'] = session_start_end['start_time'] + (session_start_end['end_time'] - session_start_end['start_time']) / 2
# ミッドスリープタイムの期間を1分に設定
one_minute = timedelta(minutes=1)
session_start_end['mid_sleep_start'] = session_start_end['mid_sleep_time'] - one_minute / 2
session_start_end['mid_sleep_end'] = session_start_end['mid_sleep_time'] + one_minute / 2
# ミッドスリープタイムのデータフレームを作成
mid_sleep_data = pd.DataFrame({
'data_source': 'Mid_sleep_time',
'Type': 'Other',
'in_bed_time': pd.NaT,
'start_time': session_start_end['mid_sleep_start'],
'end_time': session_start_end['mid_sleep_end'],
'sleep_state': 10,
'session_id': session_start_end['session_id']
})
# sleep_dataにミッドスリープタイムのデータを追加
sleep_data = pd.concat([sleep_data, mid_sleep_data], ignore_index=True)睡眠データをCSVファイルとして保存する(任意項目: 保存しなくても問題ありません)
- 以下のセルを実行することで、睡眠データをCSVファイルとして保存することが可能です
- 保存しなくとも分析に問題はありません
- CSVファイルは以下の構成となっています
data_source: インポートしたデータセットの名前です(基本的にはGoogle Fitから取得されたデバイスの名前です)Mid_sleep_time: 算出されたミッドスリープタイム
Type: 基本的にはAutoかManualのどちらかが入りますAuto: 自動で睡眠記録が開始・停止していることを意味しますManual: 手動で睡眠記録が開始・停止していることを意味しますOther: 算出されたミッドスリープタイムであることを意味します
in_bed_time: 手動で睡眠記録を開始している場合、その開始時刻が入りますstart_time: 各睡眠ステージが開始された時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)end_time: 各睡眠ステージが終了した時刻で、協定世界時(UTC)となっています(日本標準時ではないことに注意してください)sleep_state: Google Fitで定められた睡眠ステージの値(1~6)と、算出したミッドスリープタイム(10)が入りますsession_id: 1回の睡眠ごとに割り振られたIDです(end_timeから次のstart_timeまでの間が2時間以上離れている場合、別の睡眠とみなしています)
睡眠ステージについて
| 睡眠ステージのタイプ | 値 |
|---|---|
| 覚醒(睡眠サイクル中) | 1 |
| 睡眠 | 2 |
| ベッド外 | 3 |
| 浅い睡眠 | 4 |
| 深い睡眠 | 5 |
| レム睡眠 | 6 |
| ミッドスリープタイム | 10 |
(おそらくですが)睡眠ステージ2はデータの信頼性が低く使われていない傾向にあります ミッドスリープタイムはオリジナル(Google Fitのデータ)にはない項目です
# CSVを保存する関数
# ユーザーのデスクトップパスを取得
desktop_path = os.path.join(os.environ['USERPROFILE'], 'Desktop')
# CSVを保存する関数
def save_csv(sleep_data, path):
sleep_data.to_csv(path, index=False)
return f'CSVファイルを {path}に保存しました。'
# 「Save」ボタンの動作を定義
def on_save_button_clicked(b):
with output:
clear_output()
if not fc.selected:
print("CSVファイルの保存先を選択してください")
else:
# ここでDataFrameを保存
result = save_csv(sleep_data, fc.selected) # dfは保存したいDataFrameの変数名
print(result)
# ファイル選択ダイアログを設定
fc = FileChooser(desktop_path)
fc.default_filename = 'sleep_data.csv'
fc.use_dir_icons = True
# 「Save」ボタンの作成
save_button = widgets.Button(
description='Save',
button_style='',
tooltip='Click to save the CSV file',
icon='check'
)
save_button.on_click(on_save_button_clicked)
# 出力エリアを設定
output = widgets.Output()
# ウィジェットを表示
display(fc, save_button, output)アクトグラムを表示するための準備を行うセル
アクトグラムとは、睡眠周期を可視化するグラフのことです。
# 日またぎを処理する関数
def adjust_end_time(start, end):
if end < start:
end += 1440 # 翌日にまたがる場合は24時間分(分)を加算
return end
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
jst_sleep_data = sleep_data.copy()
jst_sleep_data['start_time'] = convert_to_jst_if_needed(jst_sleep_data['start_time'])
jst_sleep_data['end_time'] = convert_to_jst_if_needed(jst_sleep_data['end_time'])
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
jst_sleep_data['start_time'] = jst_sleep_data['start_time'].astype('datetime64[ns, Asia/Tokyo]')
jst_sleep_data['end_time'] = jst_sleep_data['end_time'].astype('datetime64[ns, Asia/Tokyo]')
return jst_sleep_data
def plot_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {1: '#e0ffff', 2: '#b3e5fc', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10: 'yellow'}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig, ax = plt.subplots(figsize=(20, num_days * 0.4))
for _, row in filtered_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
ax.plot([row['start_minutes'], row['end_minutes']], [day_of_week, day_of_week], color=row['color'], alpha=0.7)
ax.plot([row['start_minutes'] + 1440, row['end_minutes'] + 1440], [day_of_week + 1, day_of_week + 1], color=row['color'], alpha=0.7)
ax.set_xlim(0, 2880)
ax.set_ylim(0, num_days)
ax.set_yticks(range(num_days))
ax.set_yticklabels([(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)])
ax.set_xlabel('Time')
ax.set_ylabel('Days from Start Date')
plt.title(f'Actogram from {start_date} to {end_date}')
plt.grid(True)
plt.xticks(ticks=[i * 60 for i in range(49)], labels=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)], rotation=45)
plt.show()
# データセットの範囲確認
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
start_date = jst_sleep_data['start_time'].min().strftime('%Y-%m-%d')
end_date = jst_sleep_data['start_time'].max().strftime('%Y-%m-%d')
print(f"This dataset contains data from {start_date} to {end_date}.")
↑ に表示されたのが、JSONファイルから読み込まれたデータ範囲です。
This dataset contains data from
YYYY-MM-DDtoYYYY-MM-DD
以下のセルでは、 - JSONファイルに含まれていたデータ期間に応じて、四半期(3ヶ月)ごとにアクトグラムがプロットされます - 1年につき4枚グラフが出るので、含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります - 任意の期間のアクトグラムを表示することも可能です
アクトグラムを表示せず、次のセルに進んでも構いません。
# 四半期毎にデータをプロット
start_year = jst_sleep_data['start_time'].dt.year.min()
end_year = jst_sleep_data['start_time'].dt.year.max()
last_date = jst_sleep_data['start_time'].max()
for year in range(start_year, end_year + 1):
for quarter in range(1, 5):
start_month = 3 * quarter - 2
end_month = 3 * quarter
quarter_start_date = pd.Timestamp(year=year, month=start_month, day=1).tz_localize('Asia/Tokyo')
quarter_end_date = pd.Timestamp(year=year, month=end_month, day=1).tz_localize('Asia/Tokyo') + pd.DateOffset(months=1) - pd.DateOffset(days=1)
if quarter_start_date > last_date:
break # この四半期の開始日がデータセットの最後の日を超えている場合はスキップ
if quarter_end_date > last_date:
quarter_end_date = last_date # 四半期の終了日がデータセットの最後の日を超えている場合は調整
plot_actogram(jst_sleep_data, quarter_start_date.strftime('%Y-%m-%d'), quarter_end_date.strftime('%Y-%m-%d'))任意の期間に絞ったアクトグラム
- 任意の期間に絞ったアクトグラムを、ブラウザ上に表示するセルです
- データの期間は四半期(3ヶ月)を推奨しています
- 四半期より長い期間を選択した場合、Y軸の文字が潰れてしまいます
- このセルを実行しなくても問題はありません
# 任意の期間のアクトグラム
def plot_interactive_actogram(sleep_data, start_date, end_date):
# タイムゾーン変換後のデータを取得
jst_sleep_data = convert_sleep_data_to_jst(sleep_data)
# 指定された期間でデータをフィルタリング
filtered_data = jst_sleep_data[
(jst_sleep_data['start_time'] >= pd.Timestamp(start_date).tz_localize('Asia/Tokyo')) &
(jst_sleep_data['end_time'] <= pd.Timestamp(end_date).tz_localize('Asia/Tokyo'))
].copy()
if filtered_data.empty:
print(f"No data available to plot between {start_date} and {end_date}.")
return
# 日またぎを考慮した時間の計算
filtered_data['start_minutes'] = filtered_data['start_time'].apply(lambda dt: dt.hour * 60 + dt.minute)
filtered_data['end_minutes'] = filtered_data.apply(
lambda row: adjust_end_time(row['start_minutes'], row['start_minutes'] + (row['end_time'] - row['start_time']).seconds // 60), axis=1)
color_map = {
1: '#e0ffff', # 覚醒(睡眠サイクル中)
2: '#b3e5fc', # 睡眠
3: '#ff5252', # ベッド外
4: '#03a9f4', # 浅い睡眠
5: '#303f9f', # 深い睡眠
6: '#ab47bc', # レム睡眠
10: 'black' # ミッドスリープタイム(色を強調)
}
sleep_stage_labels = {
1: '覚醒(睡眠サイクル中)',
2: '睡眠',
3: 'ベッド外',
4: '浅い睡眠',
5: '深い睡眠',
6: 'レム睡眠',
10: 'ミッドスリープタイム'
}
filtered_data['color'] = filtered_data['sleep_state'].map(color_map)
num_days = max(1, (pd.Timestamp(end_date) - pd.Timestamp(start_date)).days + 1)
fig = go.Figure()
for sleep_state, color in color_map.items():
sleep_state_data = filtered_data[filtered_data['sleep_state'] == sleep_state]
if not sleep_state_data.empty:
for _, row in sleep_state_data.iterrows():
day_of_week = (row['start_time'] - pd.Timestamp(start_date).tz_localize('Asia/Tokyo')).days
line_width = 7.5 if sleep_state == 10 else 5 # ミッドスリープタイムの場合は線の太さを15に設定
y_offset = 0 if sleep_state == 10 else 0 # ミッドスリープタイムの場合はy座標をさらにオフセット
opacity = 1 if sleep_state == 10 else 0.5 # ミッドスリープタイム以外は透明度を0.3に設定
fig.add_trace(go.Scatter(
x=[row['start_minutes'], row['end_minutes']],
y=[day_of_week + y_offset, day_of_week + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
fig.add_trace(go.Scatter(
x=[row['start_minutes'] + 1440, row['end_minutes'] + 1440],
y=[day_of_week + 1 + y_offset, day_of_week + 1 + y_offset],
mode='lines',
line=dict(color=row['color'], width=line_width),
name=sleep_stage_labels[sleep_state],
text=f"{row['start_time'].strftime('%Y-%m-%d %H:%M')} to {row['end_time'].strftime('%Y-%m-%d %H:%M')}",
hoverinfo='text',
opacity=opacity
))
# 凡例を統合
unique_labels = set()
fig.for_each_trace(lambda trace: trace.update(showlegend=False) if trace.name in unique_labels else unique_labels.add(trace.name))
fig.update_layout(
title=f'Interactive Actogram from {start_date} to {end_date}',
xaxis_title='Time',
yaxis_title='Days from Start Date',
xaxis=dict(
tickmode='array',
tickvals=[i * 60 for i in range(49)],
ticktext=[f'{(i % 24):02d}:00' if i % 2 == 0 else '' for i in range(49)],
range=[0, 2880]
),
yaxis=dict(
tickvals=list(range(num_days)),
ticktext=[(pd.Timestamp(start_date).tz_localize('Asia/Tokyo') + pd.Timedelta(days=x)).strftime('%Y-%m-%d') for x in range(num_days)],
range=[0, num_days],
tickfont=dict(size=10) # Y軸ラベルの文字サイズを小さく
),
hovermode='closest',
legend=dict(
itemsizing='constant'
)
)
pio.write_html(fig, file='sleep_data_plot.html', auto_open=True)
# ウィジェットの作成
start_date_picker = widgets.DatePicker(
description='Start Date',
disabled=False
)
end_date_picker = widgets.DatePicker(
description='End Date',
disabled=False
)
interactive_button = widgets.Button(
description='Plot Interactive Actogram',
button_style='info',
tooltip='Click to plot the interactive actogram',
icon='line-chart'
)
notice_label = widgets.Label(
value='データ範囲は四半期(3ヶ月)程度にしてください。それ以上の期間を指定すると文字が潰れて読めなくなります。また、グラフの作成には少し時間がかかります。'
)
# ボタンがクリックされたときの動作
def on_button_clicked(b):
start_date = start_date_picker.value
end_date = end_date_picker.value
if start_date is not None and end_date is not None:
plot_interactive_actogram(sleep_data, start_date, end_date)
else:
print("Please select both start and end dates.")
interactive_button.on_click(on_button_clicked)
# ウィジェットの表示
display(notice_label, start_date_picker, end_date_picker, interactive_button)睡眠の統計分析を行うセル
以下のセルでは、 1. 四半期ごとの睡眠時間及び睡眠の質の推移の可視化(折れ線グラフ) - 1枚 2. 四半期の範囲で曜日別の睡眠時間及び睡眠の質の可視化(箱ひげ図) - 1年につき4枚 を行います。
含まれているデータ期間が長い場合は、全部のグラフが出力されるまで時間がかかります。 そのため、実行せず、次のセルに進んでも構いません。
def calculate_sleep_quality(sleep_data):
# 各セッションの睡眠時間を計算
session_start_end = sleep_data.groupby('session_id').agg(
start_time=('start_time', 'min'),
end_time=('end_time', 'max')
).reset_index()
session_start_end['sleep_duration_total'] = (session_start_end['end_time'] - session_start_end['start_time']).dt.total_seconds() / 3600
# 深い睡眠の割合を計算
sleep_data['sleep_duration'] = (sleep_data['end_time'] - sleep_data['start_time']).dt.total_seconds() / 3600
deep_sleep_data = sleep_data[sleep_data['sleep_state'] == 5] # 深い睡眠
deep_sleep_duration = deep_sleep_data.groupby('session_id')['sleep_duration'].sum().reset_index()
# 列名を変更
deep_sleep_duration.rename(columns={'sleep_duration': 'sleep_duration_deep'}, inplace=True)
sleep_quality = pd.merge(session_start_end, deep_sleep_duration, on='session_id', how='left')
sleep_quality['sleep_quality'] = sleep_quality['sleep_duration_deep'].fillna(0) / sleep_quality['sleep_duration_total']
return sleep_quality[['session_id', 'sleep_duration_total', 'sleep_quality']]
def calculate_quarterly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
quarterly_stats = sleep_data.groupby('quarter').agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return quarterly_stats
def plot_quarterly_sleep_stats(quarterly_stats):
fig, ax1 = plt.subplots(figsize=(18, 6))
ax1.set_xlabel('Quarter')
ax1.set_ylabel('Average Sleep Time (hours)', color='tab:blue')
ax1.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_time'], color='tab:blue', marker='o', label='Avg Sleep Time')
ax1.tick_params(axis='y', labelcolor='tab:blue')
ax2 = ax1.twinx()
ax2.set_ylabel('Average Sleep Quality', color='tab:orange')
ax2.plot(quarterly_stats['quarter'].astype(str), quarterly_stats['avg_sleep_quality'], color='tab:orange', marker='o', linestyle='--', label='Avg Sleep Quality')
ax2.tick_params(axis='y', labelcolor='tab:orange')
fig.tight_layout()
fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9))
plt.title('Quarterly Average Sleep Time and Quality')
plt.show()
def calculate_weekly_sleep_stats(sleep_data):
sleep_quality = calculate_sleep_quality(sleep_data)
sleep_data = pd.merge(sleep_data, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekly_stats = sleep_data.groupby(['quarter', 'weekday']).agg(
avg_sleep_time=('sleep_duration_total', 'mean'),
avg_sleep_quality=('sleep_quality', 'mean')
).reset_index()
return weekly_stats
def plot_weekly_sleep_stats_boxplot(sleep_data_jst):
sleep_quality = calculate_sleep_quality(sleep_data_jst)
sleep_data = pd.merge(sleep_data_jst, sleep_quality, on='session_id')
sleep_data['quarter'] = sleep_data['start_time'].dt.to_period('Q')
sleep_data['weekday'] = sleep_data['start_time'].dt.day_name()
weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_colors = ['#3498db', '#3498db', '#3498db', '#3498db', '#3498db', '#e74c3c', '#e74c3c'] # 平日は青、土日は赤
weekday_palette = dict(zip(weekdays, weekday_colors))
for quarter in sleep_data['quarter'].unique():
quarter_data = sleep_data[sleep_data['quarter'] == quarter]
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12))
# 睡眠時間の箱ひげ図
sns.boxplot(x='weekday', y='sleep_duration_total', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax1, hue='weekday', dodge=False)
ax1.set_title(f'Weekly Sleep Duration for {quarter}')
ax1.set_xlabel('Weekday')
ax1.set_ylabel('Sleep Duration (hours)')
ax1.legend([],[], frameon=False) # レジェンドを非表示にする
# 睡眠の質の箱ひげ図
sns.boxplot(x='weekday', y='sleep_quality', data=quarter_data, order=weekdays, palette=weekday_palette, ax=ax2, hue='weekday', dodge=False)
ax2.set_title(f'Weekly Sleep Quality for {quarter}')
ax2.set_xlabel('Weekday')
ax2.set_ylabel('Sleep Quality')
ax2.legend([],[], frameon=False) # レジェンドを非表示にする
plt.tight_layout()
plt.show()
# データの準備
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
# 四半期ごとの統計を計算
quarterly_stats = calculate_quarterly_sleep_stats(sleep_data_jst)
# 結果をプロット
plot_quarterly_sleep_stats(quarterly_stats)
# 曜日別の統計を計算
weekly_stats = calculate_weekly_sleep_stats(sleep_data_jst)
# 結果を箱ひげ図でプロット
plot_weekly_sleep_stats_boxplot(sleep_data_jst)任意の日付による、睡眠セッションの可視化
以下のセルでは、ユーザーが指定した日付の睡眠セッション分析し、睡眠ステージの推移をグラフに表示します。
def convert_to_jst_if_needed(column):
# タイムゾーン情報を確認し、必要に応じて変換を行う
if column.dt.tz is None:
# タイムゾーン情報がない場合、UTCとして解釈し、JSTに変換
return pd.to_datetime(column, utc=True).dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) == 'UTC':
# タイムゾーンがUTCであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
elif str(column.dt.tz) != 'Asia/Tokyo':
# タイムゾーンがJSTでない他のタイムゾーンであれば、JSTに変換
return column.dt.tz_convert('Asia/Tokyo')
else:
# 既にJSTであればそのまま返す
return column
def convert_sleep_data_to_jst(sleep_data):
# sleep_dataをコピーしてタイムゾーンを変換
sleep_data_jst = sleep_data.copy()
sleep_data_jst['start_time'] = convert_to_jst_if_needed(sleep_data_jst['start_time'])
sleep_data_jst['end_time'] = convert_to_jst_if_needed(sleep_data_jst['end_time'])
if 'in_bed_time' in sleep_data.columns:
sleep_data_jst['in_bed_time'] = convert_to_jst_if_needed(sleep_data_jst['in_bed_time'])
else:
sleep_data_jst['in_bed_time'] = None
# 明示的に datetime64[ns, Asia/Tokyo] にキャスト
sleep_data_jst['start_time'] = sleep_data_jst['start_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['end_time'] = sleep_data_jst['end_time'].astype('datetime64[ns, Asia/Tokyo]')
sleep_data_jst['in_bed_time'] = sleep_data_jst['in_bed_time'].astype('datetime64[ns, Asia/Tokyo]')
return sleep_data_jst
def create_session_data(sleep_data_jst):
# 各セッションの最終 'end_time' を取得して日付に変換
session_dates = sleep_data_jst.groupby('session_id')['end_time'].max().dt.date
session_dates = session_dates.reset_index()
session_dates.rename(columns={'end_time': 'session_date'}, inplace=True)
# 睡眠時間と睡眠潜時の計算
sleep_times = sleep_data_jst.groupby('session_id').agg(
sleep_time=('end_time', lambda x: (x.max() - x.min()).total_seconds() / 3600),
start_time=('start_time', 'min')
)
sleep_times.reset_index(inplace=True)
# 睡眠潜時の計算
sleep_latency = sleep_data_jst.groupby('session_id').apply(
lambda group: calculate_sleep_latency(group[['in_bed_time', 'start_time', 'Type', 'sleep_state']]),
include_groups=False # 追加: グループ化列を適用操作から除外
).reset_index(name='sleep_latency')
# 結合して全データを含むデータフレームを作成
full_session_data = pd.merge(session_dates, sleep_times[['session_id', 'sleep_time']], on='session_id')
full_session_data = pd.merge(full_session_data, sleep_latency, on='session_id')
return full_session_data
def calculate_sleep_latency(group):
group = group.sort_values(by='start_time')
auto_sleep_times = group[(group['Type'] == 'Auto') & (group['sleep_state'] >= 4)]
if not auto_sleep_times.empty:
auto_sleep_time = auto_sleep_times['start_time'].iloc[0]
if pd.notna(group['in_bed_time'].iloc[0]) and group['in_bed_time'].iloc[0] <= group['start_time'].iloc[0]:
return (auto_sleep_time - group['in_bed_time'].iloc[0]).total_seconds() / 60
return np.nan
sleep_data_jst = convert_sleep_data_to_jst(sleep_data)
full_session_data = create_session_data(sleep_data_jst)
# 日付選択ウィジェット
date_picker = DatePicker(description='Select Date', disabled=False)
def on_prev_clicked(b):
date_picker.value = date_picker.value - pd.Timedelta(days=1) if date_picker.value else None
def on_next_clicked(b):
date_picker.value = date_picker.value + pd.Timedelta(days=1) if date_picker.value else None
button_prev = Button(description="Previous Day")
button_next = Button(description="Next Day")
button_prev.on_click(on_prev_clicked)
button_next.on_click(on_next_clicked)
display(HBox([button_prev, button_next]))
display(date_picker)
# タイムゾーンを確認して適切に日付を表示する関数
def set_plot_title(ax, session_id, sleep_data_jst):
jst = pytz.timezone('Asia/Tokyo')
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
if session_data['start_time'].dt.tz:
start_time_jst = session_data['start_time'].min().astimezone(jst)
end_time_jst = session_data['end_time'].max().astimezone(jst)
else:
start_time_utc = session_data['start_time'].min().replace(tzinfo=pytz.utc)
end_time_utc = session_data['end_time'].max().replace(tzinfo=pytz.utc)
start_time_jst = start_time_utc.astimezone(jst)
end_time_jst = end_time_utc.astimezone(jst)
title = f"Sleep Session from {start_time_jst.strftime('%Y-%m-%d %H:%M')} to {end_time_jst.strftime('%Y-%m-%d %H:%M')}"
ax.set_title(title)
else:
ax.set_title("No data available for this session")
# キャプションを追加する関数
def add_caption(ax, session_id, full_session_data):
record = full_session_data[full_session_data['session_id'] == session_id].iloc[0]
# キャプションの初期部分
caption = f"睡眠時間: {record['sleep_time']:.2f} 時間\n"
# sleep_latencyがNaNやマイナスでない場合のみ追加
if pd.notna(record['sleep_latency']) and record['sleep_latency'] >= 0:
caption += f"睡眠潜時(布団に入ってから寝付くまでの時間): {record['sleep_latency']:.2f} 分"
ax.text(0.01, 0.95, caption, transform=ax.transAxes, fontsize=12, verticalalignment='top')
# 睡眠データをプロットする関数
def plot_sleep_data(session_id, sleep_data_jst, full_session_data):
session_info = full_session_data[full_session_data['session_id'] == session_id]
session_data = sleep_data_jst[sleep_data_jst['session_id'] == session_id]
if not session_data.empty:
# 日時データのタイムゾーンを確認し、日本時間に設定
if session_data['start_time'].dt.tz is None:
session_data['start_time'] = session_data['start_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
if session_data['end_time'].dt.tz is None:
session_data['end_time'] = session_data['end_time'].dt.tz_localize('UTC').dt.tz_convert('Asia/Tokyo')
fig, ax = plt.subplots(figsize=(20, 7))
stage_height = {3: 5, 1: 4, 4: 3, 6: 2, 5: 1, 10: 6}
stage_colors = {1: '#e0ffff', 3: '#ff5252', 4: '#03a9f4', 5: '#303f9f', 6: '#ab47bc', 10:'yellow'}
data_sources = session_data['data_source'].unique()
source_count = len(data_sources)
alpha_value = 1 / source_count if source_count > 0 else 1
# プロットの時間を日本時間に合わせて設定
for index, row in session_data.iterrows():
start_pos = mdates.date2num(row['start_time'])
duration = mdates.date2num(row['end_time']) - start_pos
ax.bar(x=start_pos, height=stage_height[row['sleep_state']], width=duration,
color=stage_colors.get(row['sleep_state'], '#FFFFFF'), edgecolor='black',
align='edge', alpha=alpha_value)
ax.xaxis_date(tz=timezone('Asia/Tokyo'))
ax.xaxis.set_major_locator(mdates.HourLocator(interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M', tz=timezone('Asia/Tokyo')))
ax.set_ylim(0, 6)
ax.set_yticks([1, 2, 3, 4, 5, 6])
ax.set_yticklabels(['Deep Sleep', 'REM', 'Light Sleep', 'Awake', 'Out-of-bed', 'Mid Sleep Time'])
ax.set_xlabel('Time of Day')
set_plot_title(ax, session_id, sleep_data_jst)
add_caption(ax, session_id, session_info)
plt.tight_layout()
plt.show()
else:
print("No sleep data available for this session.")
# 日付変更時のイベントハンドラ
def on_date_change(change):
if change['new'] is not None:
selected_date = pd.to_datetime(change['new']).date()
session_id = next((sid for sid, date in full_session_data.set_index('session_id')['session_date'].items() if date == selected_date), None)
if session_id is not None:
plot_sleep_data(session_id, sleep_data_jst, full_session_data)
else:
print("No sessions found for this date.")
date_picker.observe(on_date_change, names='value')7. おわりに
この記事及びJupyter Notebookが誰かのお役に立てれば幸いです。
参考文献
Google for Developers (2023)“Read Sleep Data”, Google for Developers, 2023 Accessed May 23, 2024 https://developers.google.com/fit/scenarios/read-sleep-data
Jeffrey A. Elliott Carl Hirschie Johnson & Russell Foster (2003)“Entrainment of circadian programs”, Chronobiology International, vol. 20, No. 5, pp. 741–774
Ozgur Tataroglu & Patrick Emery (2014)“Studying circadian rhythms in drosophila melanogaster”, Methods, vol. 68, No. 1, pp. 140–150
Roberto Refinetti, Germaine Corné Lissen & Franz Halberg (2007)“Procedures for numerical analysis of circadian rhythms”, Biological Rhythm Research, vol. 38, No. 4, pp. 275–325
Colin S Pittendrigh (1960)“Circadian rhythms and the circadian organization of living systems”, Cold Spring Harbor Symposia on Quantitative Biology, vol. 25, pp. 159–184
M. S. Johnson (1926)“Activity and Distribution of Certain Wild Mice in Relation to Biotic Communities1”, Journal of Mammalogy, vol. 7, No. 4, pp. 245–277