JSON CanvasからMarkdownへ変換するPythonスクリプトを作成しました
スクリプト
How2
おすすめ記事
キャンバスツールによるVisual Thinkingをテキストへ

本サイトは広告やアフィリエイトプログラムにより収益を得ています
要旨
JSON Canvasと呼ばれるオープンソースの無限キャンバスツールで作成された.canvasデータをMarkdownファイルに変換するPythonスクリプトを作成し、GitHubで公開しました。 無限キャンバスツールは小説やゲームのシナリオなどに関するメモを二次元空間に自由に配置し、メモ同士を線や矢印で繋ぐことでプロットを作成するのに便利ですが、そのプロットをファイルとして出力することは容易ではありませんでした。 本スクリプトではノードとエッジの情報をローカルで解析し、矢印で繋がれたメインストーリー, それに関するメモ, そして孤立したメモの3つに分類したあと、それらを1つのMarkdownファイルにまとめて出力します。 これにより、無限キャンバスの内容をテキストファイルに落とし込むという事務作業から開放され、より一層創作活動に専念できるようになります。
背景
無限キャンバスツールは目新しいものではないものの、近年、急速に普及が進み、また多くのサービスが提供されています(Arun and Muse 2022)。例えば、Miroや、Figmaなどは一度は耳にしたことがあるのではないでしょうか。他にも、Arcというブラウザアプリはイーゼルと呼ばれる無限キャンバスを内蔵していますし(Arc 2022)、AppleではiPhone, iPad, Mac向けにFreeform(日本ではフリーボード)と呼ばれるアプリを提供しており(Apple Japan 広報部 2022)、iPadにはそれが内蔵されています。今回紹介するObsidianにも古くからコミュニティプラグイン(有志による拡張機能)という形でExcalidrawが提供されています。
こうした無限キャンバスツールは大きなホワイトボードのようなものなので、付箋をペタペタ貼ったり、ラフなアイデアを落書きしてみたりといった形で頭の中に眠っていたアイデアをアウトプットし、整理するのにはとても便利です(図 1)。無限キャンバスという名前の通り無限にスペースを広げられ、制約もありません。

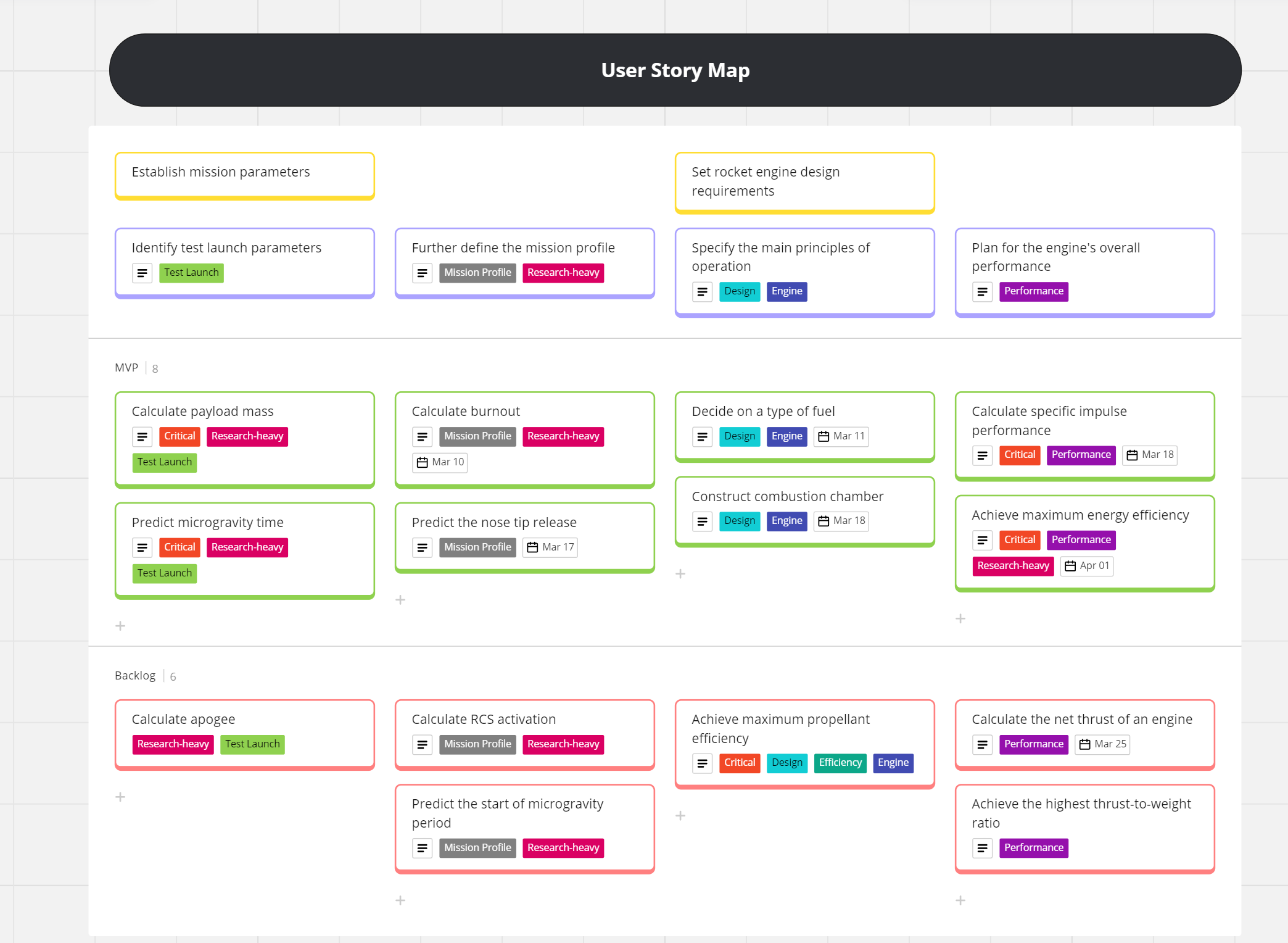
しかし、その無限に発散したアイデアを1つに収束させ形にする必要がでた時、人によっては苦痛にもなる作業――つまり、情報を取捨選択し筋道立てて再構成し、メモを転記するというアクション――が発生します。もちろん、キャンバスの内容はある程度整理しているはずですし、アウトプットするという過程も、思考を深めるには大事な行為であることは理解していますが、メモをコピペしている瞬間というのは退屈で出来れば自動化したい時間です。
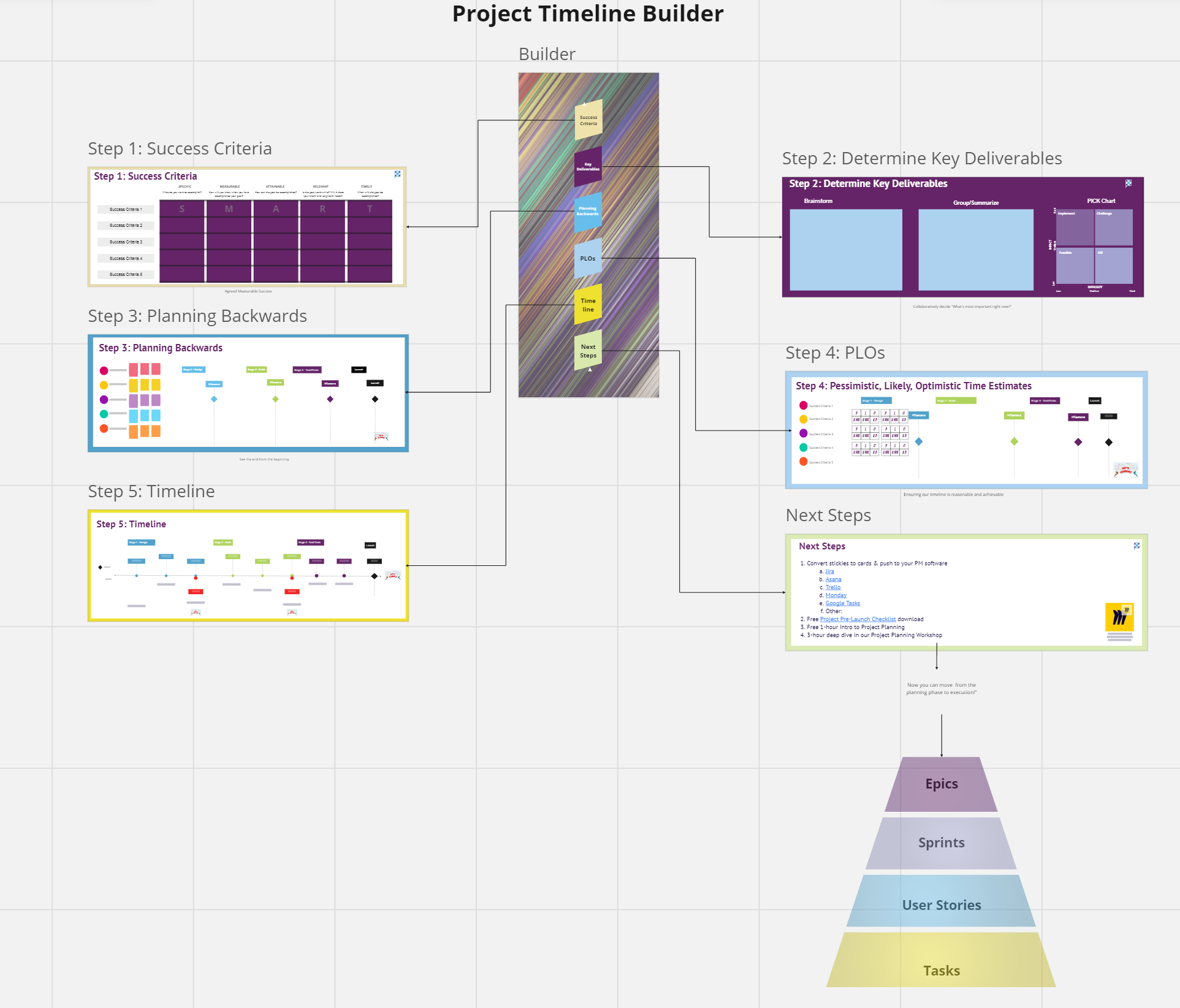
話は変わりますが、筆者は現在、同人ゲームを一人で開発しています。いわゆるノベルゲーと呼ばれる物語を中心としたゲームのため、プロットを考え, その情景を詳細に想像し, 背景やキャラの立ち絵・表情の変化などを考え, セリフや文章・画面演出を練って脚本を書き, それを元にスクリプトを書いています。また、用語集を使ったWikiを作成しアイデアとアイデアを結びつけるといったこともしています(図 2)。そういう時に役立つのが、Obsidianというツールです。
Obsidianを使うことで無限キャンバスを使ったプロット作成や、Markdown形式1で絵や演出案(スクリプト)を含めた脚本執筆が行える他、自分用のWikiも簡単に作ることが出来ています。Markdown形式で書かれた脚本やWikiは、言ってしまえば単なるテキストデータのため簡単に他の形式(HTMLやPDFなど)に変換することができます。また、脚本から必要な地の文, 話者・セリフを取り出すことも工夫次第ではできるため、筆者は脚本からゲームのスクリプト(.ksファイル)を作成しています。
やや話が逸れてしまいましたが、要するにMarkdownファイル(.md)は扱いやすいという話です。無限キャンバスで書かれたアイデアもこんな感じで自動的にMarkdownファイルに出来れば便利だと思いませんか?
JSON Canvasとは何か
JSON Canvasは、Obsidianが2024年3月にリリースしたオープンソースの無限キャンバス機能です(Kepano 2024)。無限に広がるキャンバス上にノードとエッジを配置し、自由に結びつけることでネットワーク状の情報構造を表現できます。ノードにはテキストやファイル、リンクなどを埋め込むことができ、それらをエッジ(線や矢印)で繋げることで関係性を可視化できます(図 3)。
オープンソースのため、仕様も明確ですし、これから対応サービスが増えていくことが予想されます。なお、2024年5月現在、対応サービスはObsidian, Kinopio, Flowchart Fun, hi-canvasとなっています。
また、JSON Canvas(.cavas)のデータ形式は、拡張子こそ見慣れないものの、その中身は一般的なJSON形式(.json)が採用されています。 JSON形式はAIにとって分かりやすい書式なので、(試していませんが)そのまま生成AIに渡せばいい感じに処理してくれると考えられます。 しかし、未発表の作品を生成AIに渡してしまうのは躊躇われることでしょう。学習されてしまったり、謎の倫理観によってセンシティブ判定されてしまったり、あるいは単純にコストの問題もあります。
Obsidianとは何か
余談です
このコラムは筆者がObsidianを布教するためのものです。 読み飛ばしても問題ありません。いつか、別の記事でちゃんと解説したいと思っています。
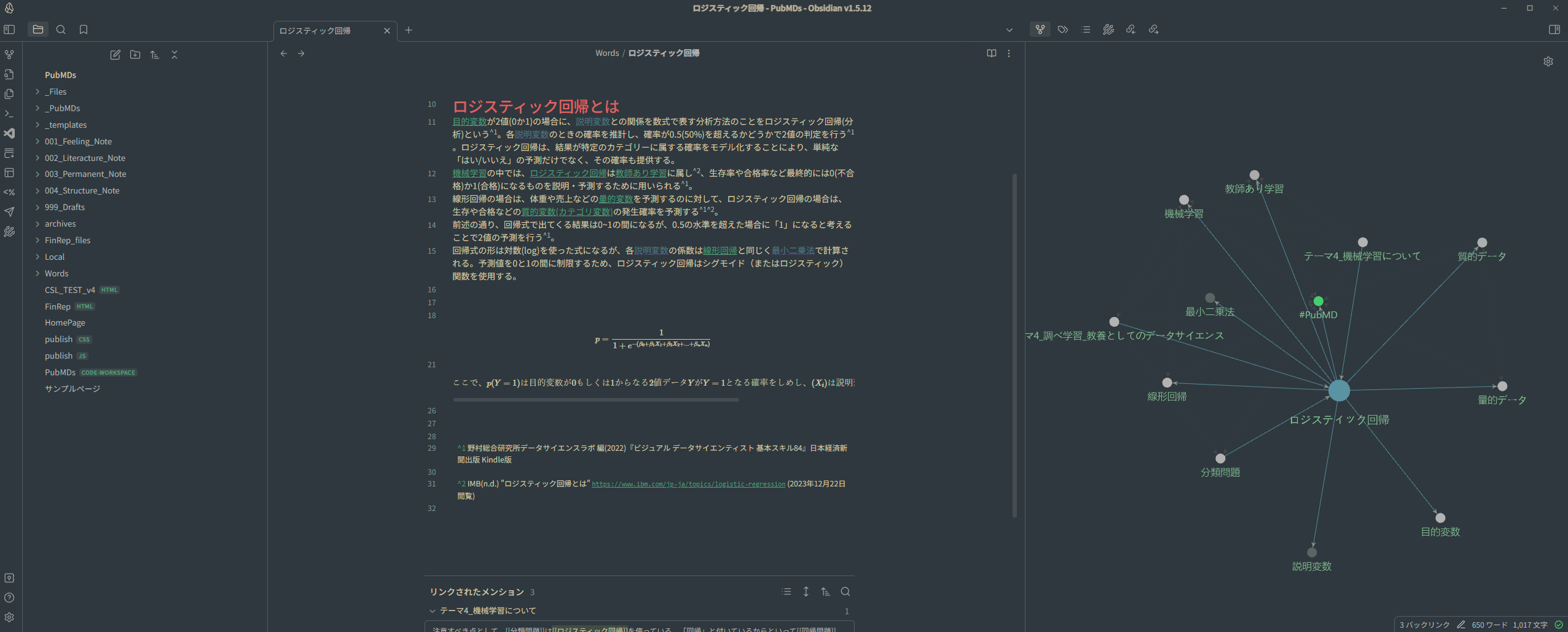
Obsidianは個人用ナレッジマネジメントシステムとして設計されたノートテイキングアプリケーションです。 その特徴は大きく5つほどあり、①ローカルで動作・管理されること(クラウド同期・マルチデバイスにも対応), ②Markdownを用いることで頑強かつ汎用性があること, ③メモ同士を繋ぐグラフビューによる可視化が可能なこと, ④マウスホバーによるインライン表示が可能なこと, ⑤コミュニティプラグインと呼ばれる有志による拡張機能が豊富なことが挙げられ、特に①~③の特徴から、「第二の脳(Second Brain)」のツールとして着目されています。
例えば、クラウド上のメモサービス(Evernote, Notion, Google Keepなど)は、あくまでオンラインが前提であり、またサービスが終了してしまった場合、自分でデータをエクスポートしないとデータはおそらく消えてしまうことでしょう。また、データ検索もサーバーや回線の具合によってはうまくいかないことがあります。その点、Obsidianはオフライン(ローカル環境)が前提のアプリで、メモは全てデバイス上にMarkdownファイルとして保存されます。 Markdown(.md)はシンプルで読みやすいテキストベースのマークアップ言語であり、広く普及しているため、たとえObsidianがサービス終了したとしても問題なく他のアプリやテキストエディタ上で読むことができます。
動機
前述の通り、筆者は同人ゲームを一人で制作しており、プロットも脚本も自分で考え、それをスクリプトに落とし込む必要があります。以前は何も考えずに無限キャンバスサービスのMiroを使っていたのですが、何だがそのうち面倒になってしまい 今ではプロットを書かずに時系列に沿って思いつきでシナリオを書いています。 この、なんだか面倒というのは多分創作活動において良くないことで、こうした摩擦を減らして如何にストレス無くアイデアを形にするかが大事なんだと思います。
そんなことを漠然と考えながら、創作もせずダラダラとTwitterを見ていたところ、碌星らせん(@dddrill)さんの以下のTweetを受けて、「確かにホワイトボード(無限キャンバスツール)に貼った付箋や落書きを良しなにテキストに出力できたら楽だろうなぁ」と思った次第であります。もちろん、筆者は創作作業から逃げてダラダラとTwitterをしている人間ですので、そんなツールがあればいいなぁと漠然と思うだけで、そんなツールがないかを自分で調べたりすることもなく、酔生夢死な日々を送っていました。
うーん、ひとまずメモ書きを二次元空間に自由に配置できて、メモ書き同士を線で繋げて、順番が決まったらくっつけて出力できるツールがあればいいのか。
— 碌星らせん(ろくせい・らせん) ((dddrill?)) May 7, 2023
何となく、何かないかなぁと頭の片隅で燻り続けて約1年。なぜか唐突に火がつき、「Obsidian CanvasはJSONファイルだから簡単に構造を把握して取り出せるはず!」と突貫工事で作業を開始した次第であります。
このスクリプトが目指すもの(このスクリプトで何ができるか)
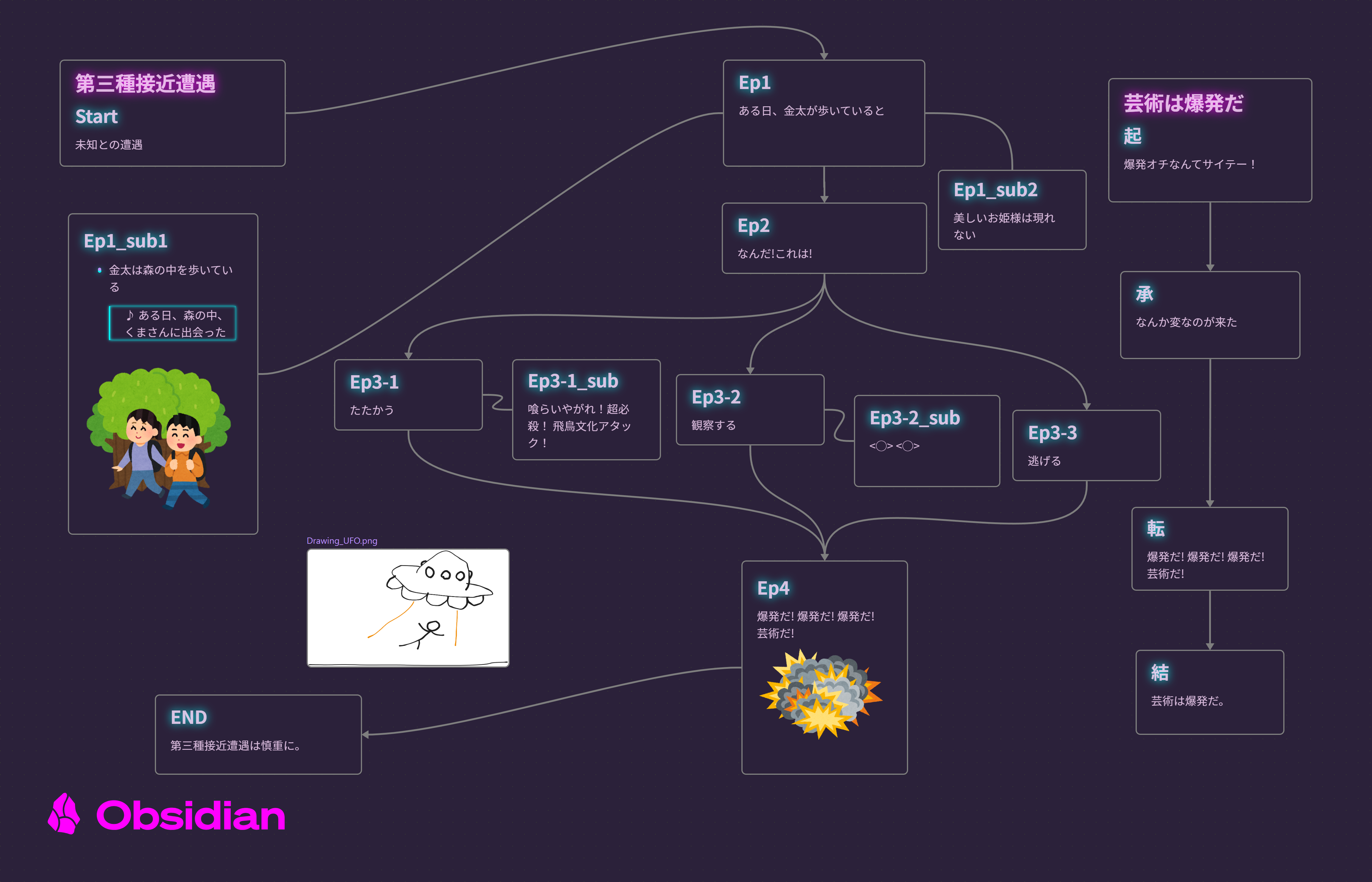
このスクリプト(スクリプト 1)ではJSON Canvas(.canvas)ファイルを読み込み、その構造を元に、矢印で繋がれたメインストーリー, それに関するメモ, そして孤立したメモの3つに分類し、矢印の順番に沿ってメインストーリーの内容をMarkdownに変換, それに関するメモを脚注として変換, 孤立したメモを水平線で区切ってその下にMarkdownとして変換し、1つのファイルにします。
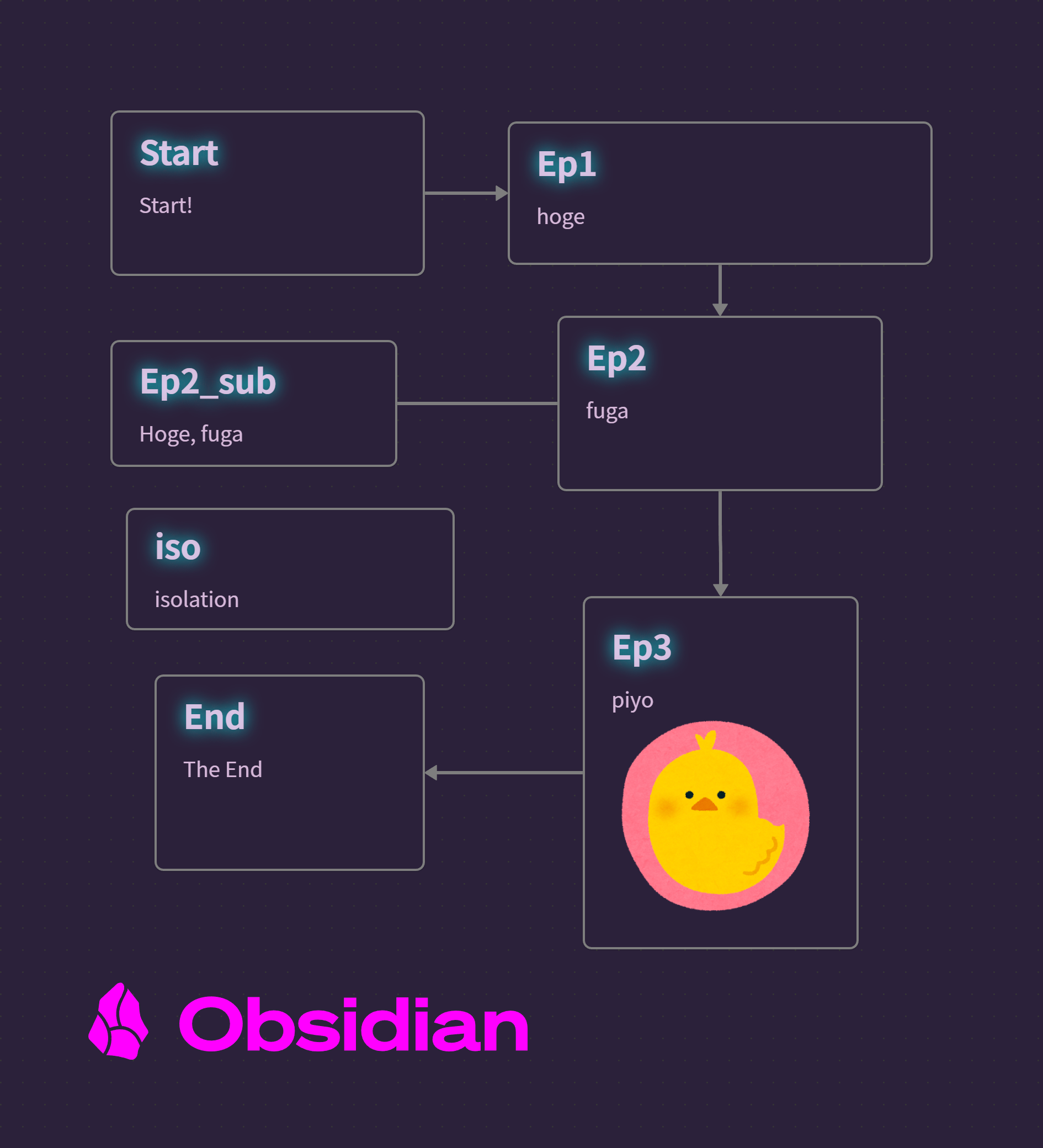
上記のような構造(図 4)のJSON Canvasファイルがあった場合、
"Canvas2MD_Sample.md
## Start
Start!
## Ep1
hoge
## Ep2
fuga
[^sub_id]
## Ep3
piyo

## End
The End
[^sub_id]:
## Ep2_sub
Hoge, fuga
---
## iso
isolation
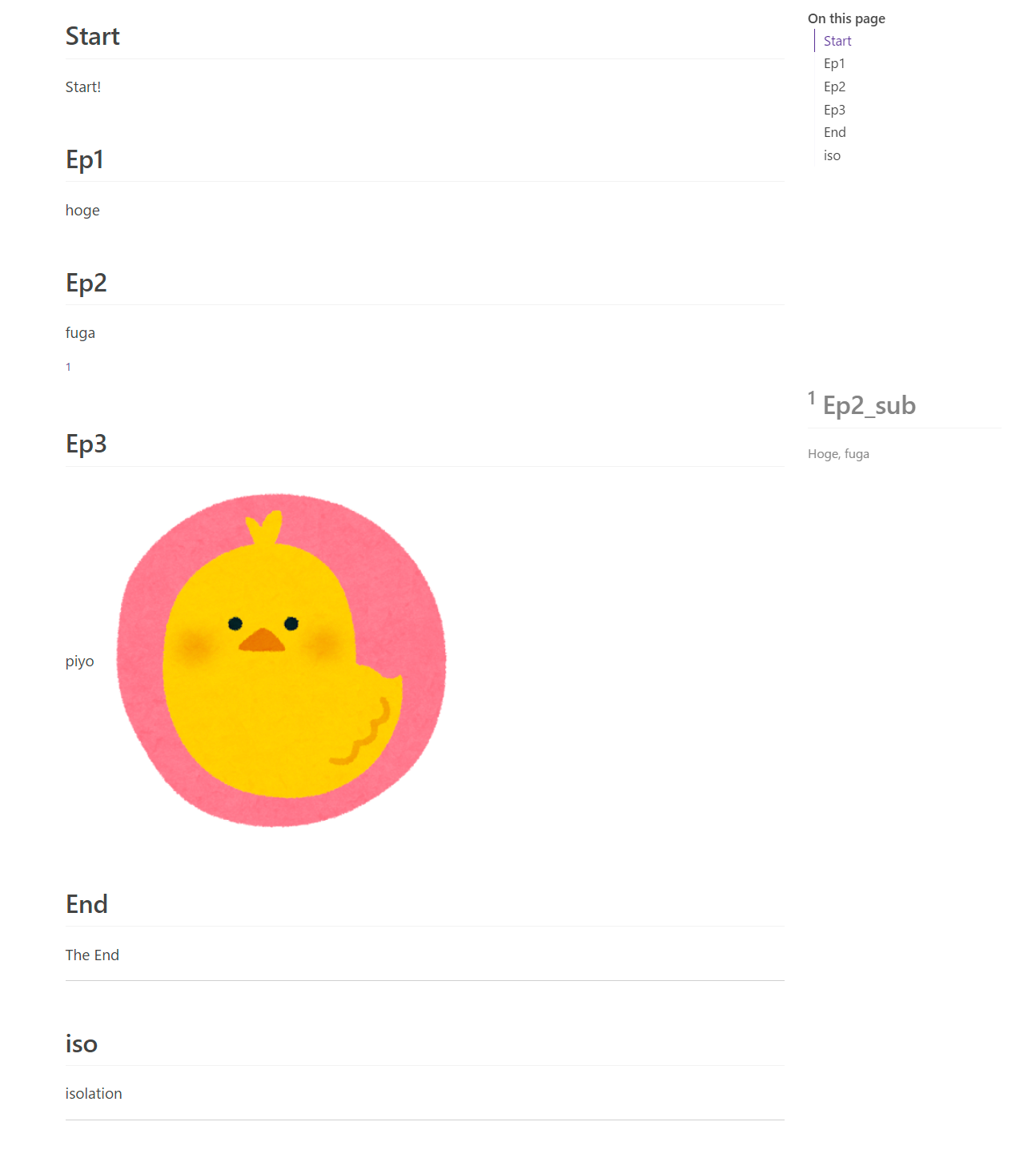
---というMarkdownに変換します。 Markdownのプレビューはどのアプリを使うかによって若干の違いが出ますが、図 5のような仕上がりになります。


材料と方法
このスクリプト(スクリプト 1)は、(今のところ)特定の構造を保ったJSON Canvasファイル(.canvas)に対して、適切なMarkdownファイル(.md)を作成します。それ以外のファイルでの動作は保証していません。
canvas_file (line 154)において、読み込むJSON Canvasファイルをフルパスで入力します。output_markdown_file (line 155)において、Markdownファイルの出力先を指定します。Canvasファイルと違うディレクトリの場合、JSON Canvas中に埋め込んだMarkdownファイルや画像がうまく表示されない場合があります。Canvas2MD.pyを実行することで、指定したJSON Canavsファイル(.canvas)を指定した場所にMarkdownを出力します。
Canvas2MD.py
import json
# メインストーリー(main_story)の定義: ノード同士が一方向矢印で結ばれた一連のノード
# サブストーリー(sub_story)の定義: メインストーリーのノードに対して矢印ではなく**線**で結ばれた**1つの**ノード
# セレクトストーリー(select_story)の定義: メインストーリー中の分岐した**1つの**ノード
# 孤立したノード(isolated nodes)の定義: どのノードとも結びついていない孤立したノード
def load_canvas(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
return data
def find_starting_nodes(edges):
to_nodes = {edge['toNode'] for edge in edges}
from_nodes = {edge['fromNode'] for edge in edges}
start_nodes = from_nodes - to_nodes
return list(start_nodes)
def find_story_path(start_node, edges, follow_arrows=True):
path = [start_node]
current_node = start_node
while True:
if follow_arrows:
next_edges = [edge for edge in edges if edge['fromNode'] == current_node and edge.get('fromEnd', 'arrow') != 'none' and edge.get('toEnd', 'arrow') != 'none']
else:
next_edges = [edge for edge in edges if edge['fromNode'] == current_node and (edge.get('fromEnd') == 'none' or edge.get('toEnd') == 'none')]
if not next_edges:
break
next_node = next_edges[0]['toNode']
path.append(next_node)
current_node = next_node
return path
def extract_stories(data):
nodes = {node['id']: node for node in data['nodes']}
edges = data.get('edges', [])
main_story_edges = [edge for edge in edges if edge.get('fromEnd', 'arrow') != 'none' and edge.get('toEnd', 'arrow') != 'none']
sub_story_edges = [edge for edge in edges if edge.get('fromEnd', 'none') == 'none' or edge.get('toEnd', 'none') == 'none']
start_nodes = find_starting_nodes(main_story_edges)
main_stories = [find_story_path(start_node, main_story_edges) for start_node in start_nodes]
main_story_nodes = {node for story in main_stories for node in story}
sub_stories = []
visited_nodes = set(main_story_nodes)
sub_story_map = {}
select_stories = {}
for edge in sub_story_edges:
if edge['fromNode'] not in visited_nodes:
sub_story = find_story_path(edge['fromNode'], sub_story_edges, follow_arrows=False)
sub_story = [node_id for node_id in sub_story if node_id not in main_story_nodes]
if sub_story:
sub_stories.append(sub_story)
if edge['toNode'] not in sub_story_map:
sub_story_map[edge['toNode']] = []
sub_story_map[edge['toNode']].append(sub_story[0])
visited_nodes.update(sub_story)
elif edge['toNode'] not in visited_nodes:
sub_story = find_story_path(edge['toNode'], sub_story_edges, follow_arrows=False)
sub_story = [node_id for node_id in sub_story if node_id not in main_story_nodes]
if sub_story:
sub_stories.append(sub_story)
if edge['fromNode'] not in sub_story_map:
sub_story_map[edge['fromNode']] = []
sub_story_map[edge['fromNode']].append(sub_story[0])
visited_nodes.update(sub_story)
for story in main_stories:
for node_id in story:
connected_edges = [edge for edge in main_story_edges if edge['fromNode'] == node_id]
if len(connected_edges) > 1:
select_stories[node_id] = [edge['toNode'] for edge in connected_edges]
connected_nodes = set(edge['fromNode'] for edge in edges).union(edge['toNode'] for edge in edges)
isolated_nodes = [node['id'] for node in nodes.values() if node['id'] not in connected_nodes]
# セレクトストーリーのノードIDを取得
select_story_nodes = {node_id for node_ids in select_stories.values() for node_id in node_ids}
# セレクトストーリーがメインストーリーに含まれている場合、それを除外する
main_stories = [[node_id for node_id in story if node_id not in select_story_nodes] for story in main_stories]
return main_stories, sub_stories, isolated_nodes, sub_story_map, select_stories, select_story_nodes
def sort_nodes_by_position(node_ids, nodes):
return sorted(node_ids, key=lambda node_id: (nodes[node_id]['y'], nodes[node_id]['x']))
def node_to_markdown(node, indent_level=0, add_sub_ref_ids=None, is_select_story=False):
indent = " " * indent_level
content = "\n"
if is_select_story:
content += f'<a id="{node["id"]}"></a>\n\n'
if node['type'] == 'text':
content += f"{indent}{node['text'].replace('\n', f'\n{indent}')}\n"
elif node['type'] == 'file':
content += f"{indent}\n"
if add_sub_ref_ids:
for sub_ref_id in add_sub_ref_ids:
content += f"\n{indent}[^sub_{sub_ref_id}]\n"
return content + "\n"
def generate_markdown(data):
nodes = {node['id']: node for node in data['nodes']}
main_stories, sub_stories, isolated_nodes, sub_story_map, select_stories, select_story_nodes = extract_stories(data)
markdown_lines = []
# サブストーリーを変換するための辞書を作成
sub_story_content_map = {}
for sub_story in sub_stories:
if sub_story and sub_story[0] not in select_story_nodes:
for node_id in sub_story:
node = nodes[node_id]
sub_story_content_map[node_id] = node_to_markdown(node, indent_level=2)
for main_story in main_stories:
for node_id in main_story:
node = nodes[node_id]
# セレクトストーリーでないサブストーリーの参照IDのみ追加
add_sub_ref_ids = [ref_id for ref_id in sub_story_map.get(node_id, []) if ref_id not in select_story_nodes]
markdown_lines.append(node_to_markdown(node, add_sub_ref_ids=add_sub_ref_ids))
if node_id in select_stories:
sorted_select_nodes = sort_nodes_by_position(select_stories[node_id], nodes)
markdown_lines.append("\n")
for idx, select_node_id in enumerate(sorted_select_nodes, start=1):
markdown_lines.append(f"[セレクトストーリー_{idx}にとぶ](#{select_node_id})\n")
markdown_lines.append("\n")
for select_node_id in sorted_select_nodes:
select_node = nodes[select_node_id]
add_select_sub_ref_ids = [ref_id for ref_id in sub_story_map.get(select_node_id, []) if ref_id not in select_story_nodes]
markdown_lines.append(node_to_markdown(select_node, is_select_story=True, add_sub_ref_ids=add_select_sub_ref_ids))
markdown_lines.append("\n")
markdown_lines.append("\n")
# サブストーリーの内容を脚注として追加
for node_id, content in sub_story_content_map.items():
markdown_lines.append(f"\n[^sub_{node_id}]:")
markdown_lines.append(content)
for node_id in isolated_nodes:
node = nodes[node_id]
markdown_lines.append(f"---\n{node_to_markdown(node)}\n---")
return "\n".join(markdown_lines)
def save_markdown(content, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
file.write(content)
if __name__ == "__main__":
canvas_file = 'Canvas2MD_SampleCanvas.canvas' # 読み込むJSON Canvasファイルのパスを入力してください。
output_markdown_file = 'Sample_Canvas.md' # 作成するMarkdownファイルの出力先を指定してください。
# Canvasファイルと違うディレクトリの場合、JSON Canvas中に埋め込んだMarkdownファイルや画像がうまく表示されない場合があります。
try:
canvas_data = load_canvas(canvas_file)
markdown_content = generate_markdown(canvas_data)
save_markdown(markdown_content, output_markdown_file)
print(f"Markdown file generated and saved as {output_markdown_file}")
except Exception as e:
print(f"An error occurred: {e}")動作条件
- メインストーリー(一方向の矢印で結ばれたノード)が、一方通行であり,なおかつ(分岐した場合は)分岐が続くことなくメインストーリーに合流すること(図 6)
- サブストーリー(メインストーリーのノードと線で結ばれたノード)に矢印や他のノードがついていないこと(図 7)
必要なもの(動作環境)
- Pythonが編集できるテキストエディタ(VS Codeを推奨)
- Python 3.12.3 以降(Python 3.12.3以外での動作は確認しておりません)
- JSON Canvasファイル
結果
このスクリプト(スクリプト 1)を用いることで、図 8のような複雑な無限キャンバスも図 9のように1つのMarkdownファイルに変換できます。

なお、Obsidianはversion 1.6 からマウスホバーによる脚注のポップアップ表示に対応しました。そのため、変換されたMarkdownファイルをObsidianで開くと快適に閲覧できます(図 10)。
(2024年6月5日現在、Early access権を持つユーザーのみに解放されているバージョンですが、数日から数週間以内には、全てのユーザーが使えるようになります)
課題と展望
現在のスクリプトにはJSON Canvasが特定の構造でないと正しくMarkdownに変換されないという課題があり、JSON Canvasの解析方法もベストであるとは言えません。 将来的にはこれを改善したいと思ってはいます。思っているだけですが… どなたかサポートしてくれると嬉しいです。
現在の課題
-
- サブストーリーを脚注という扱いにしている以上、脚注に脚注をつける形になる(Quartoなど一部のアプリでは正しく表示できない)
展望
ツールは作っただけでは意味はなく、使わなければなりません。自分のために作ったツールですので、自分が一番活用してやりたいものです。今のところ、以下のように活用したいと思っております。
- 同人ゲームのプロットや脚本作り
- 知的生産の技術でいうござね法
同人ゲームへの活用
このツールを作る動機となったのが、ホワイトボード(無限キャンバス)上のアイデアをテキストに変換し、ゲーム作りを楽にしたいというものでした。
このプロットを直接使ってゲームのスクリプトに変換するということはしませんが、全体のプロットや章や節ごとのプロットを脚本に落とし込むのに使えればと思っています。
筆者の作りたいノベルゲームにおいては選択肢などによる分岐がとても重要になるので、スクリプトの改良を進めて本格的な分岐に対応できるようにしたいです。
知的生産の技術 こざね法への活用
『知的生産の技術』(梅棹 1969)というとても古い本があります。筆者は高校3年生の頃にこの本に出会い、以来ずっと読んだ時の感銘が熾火のように胸に残っており、同時にそこから学んだ知的生産の技術を活用・実行できていない悔しさや劣等感といったものが火傷のように心を苛んでいます。 1969年のものなので、とっくに時代遅れになってもおかしくない本なのですが、なんと2023年になっても色褪せておらず「アカデミックスキルズ図書リスト」(東京大学駒場図書館所蔵2023)の、しかもトップにこの本がリストアップされているようです(山本 2023)。ちなみに、それを知ったのはObsidianで知的生産の技術を活用したいと思って文献を読み漁っていたからです。
『知的生産の技術』(梅棹 1969)の何が今も輝いているのでしょうか。筆者は、それを「カード法」と「こざね法」にあると考えています。「カード法」は、同年代にドイツで活躍されていたニクラス・ルーマンのZettelkasten(ツェッテルカステン)メソッドに通じるものがあり、そちらの方が有名だと思います。このカード法(Zettelkasten)は、Obsidianが得意とするところであり、Obsidianを世に広めたい筆者としては声高らかに解説したいところなのですが、話の本筋から外れてしまうため、今回は「こざね法」の紹介だけにとどめておきます。
こざね法とは
『知的生産の技術』(梅棹 1969)の中で梅棹が紹介していた、考えをまとめ文章を構築する方法がこざね法です。
その紙きれ(B8判の小さな紙)に、いまの主題に関係のあることがらを、単語、句、またはみじかい文章で、一枚に一項目ずつ、かいてゆくのである。おもいつくままに、順序かまわず、どんどんかいてゆく。すでにたくわえられているカードも、きりぬき資料も、本からの知識も、つかえそうなものはすべて一ど、この紙きれにかいてみる。ひととおり出つくしたとおもったら、その紙きれを、机のうえ、またはタタミのうえにならべてみる。これで、その主題について、あなたの頭のなかにある素材のすべてが、さらけだされたことになる。 つぎは、この紙きれを一枚ずつみながら、それとつながりのある紙きれがほかにないか、さがす。あれば、それをいっしょにならべる。このとき、けっして紙きれを分類してはいけない。カードのしまいかたのところでも注意したことだが、知的生産の目的は分類ではない。分類という作業には、あらかじめ設定されたワクが必要である。既存のワクに素材を分類してみたところで、なんの思想もでてこない。 分類するのではなく、論理的につながりがありそうだ、とおもわれる紙きれを、まとめてゆくのである。何枚かまとまったら、論理的にすじがとおるとおもわれる順序に、その一群の紙きれをならべてみる。そして、その端をかさねて、それをホッチキスでとめる。これで、ひとつの思想が定着したのである。(梅棹 1969 括弧内引用者)
上記のこざね法を、Obsidian Canvasで実践しようというのが本項の意図するところであります。短いこざね(Obsidian Canvasで言うノード)を、まずはCanvasに思いつくままに作成し、何となくまとめます。
こざねの列がいくつもできたところで、さらにそれらのこざねどうしの関係をかんがえる。そして、論理的につながっているものを、しだいにあつめてゆく。場合によれば、こざねを解体して、くみかえることもある。ホッチキスでとめてあるだけだから、すぐちぎれ、またとめなおすことができる。この作業をつづけているうちに、あたらしい素材をおもいついたら、どんどんこざねを追加する。 こうして、論理的にまとまりのある一群のこざねの列ができると、それをクリップでとめて、それに見だしの紙きれをつける。あとは、こういうふうにしてできたこざねの列を、何本もならべて、見だしをみながら、文章全体としての構成をかんがえるのである。ここで、いわゆる起承転結ふうにならべることもできるし、もっと破格な配列をかんがえることもできよう。文章全体のバランスも、具体的にかんがえることができる。ここまでくれば、もう、かくべき内容がかたまっただけでなく、かくべき文章の構成も、ほぼできあがっているのである。あとは、かさねられたこざねの列を、上から順番に、一枚ずつとりあげてみながら、その内容を文章にかきおろしてゆけばよいのである。(梅棹 1969)
それを、矢印で繋いでしまえば、あとは保存してスクリプト(スクリプト 1)にかけるだけ、といった寸法です。
感想
- ふと思い立ってこのプロジェクトに取り掛かったので、もしかしたら先行例があるかもしれないなぁと終わってから思いました。
- もっと賢いロジックで上手い事変換してくれるスクリプトがあって欲しいです。
- 今回もChatGPT-4oの力を借りてPythonスクリプトを作成しました。
- これで誰かの創作活動等のお役に立てれば幸いです。
- ちなみに、筆者は全く捗っていません。
参考文献
Arun and Muse (2022)“Infinite Canvas Tools that work the way we think”, Infinite Canvas Tools that work the way we think, 2022 Accessed May 29, 2024 https://infinitecanvas.tools/
Arc (2022)“Easels: Capture & Create”, Arc, 2022 Accessed May 29, 2024 https://resources.arc.net/hc/en-us/articles/19231142050071-Easels-Capture-Create
Apple Japan 広報部 (2022) 「Apple、フリーボードを発表:クリエイティブなブレインストーミングと共同作業のために設計されたパワフルな新しいアプリケーション」、 Apple、2022年、閲覧日 2024年5月29日、 https://nr.apple.com/DH2c8p7EB4
kepano (2024)“Announcing JSON Canvas: an open file format for infinite canvas data”, Obsidian Blog, March 11, 2024 Accessed May 29, 2024 https://obsidian.md/blog/json-canvas/
梅棹忠夫 (1969) 『知的生産の技術(岩波新書)』、 岩波書店
山本明正 (2023) 『Obsidian 次世代型のメモアプリ: Zettelkasten 知的生産の技術を超えて』、 Akimasa Net
増井敏克 (2023) 『Obsidianで“育てる”最強ノート術 —— あらゆる情報をつなげて整理しよう』、 技術評論社
Pouhon (2023) 『Obsidianでつなげる情報管理術【完成版】』、 Kindle